Model benchmarks
A lot of people have asked me what models we use for recommendations at Spotify so I wanted to share some insights. Here’s benchmarks for some models. Note that we don’t use all of them in production.
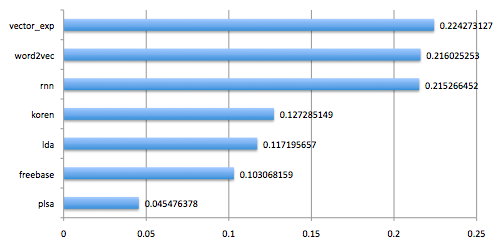 Performance for recommender models
Performance for recommender models
This particular benchmark looks at how well we are able to rank “related artists”. More info about models:
- vector_exp: Our own method, a latent factor method trained on all log data using Hadoop (50B+ events).
- word2vec: Google’s open sourced word2vec. We train a model on subsampled (5%) playlist data using skip-grams and 40 factors.
- rnn: Recurrent Neural Networks trained on session data (users playing tracks in a sequence). With 40 nodes in each layer, using Hierarchical Softmax for the output layer and dropout for regularization.
- koren: Collaborative Filtering for Implicit Feedback Datasets. Trained on same data as vector_exp. Running in Hadoop, 40 factors.
- lda: Latent Dirichlet Allocation using 400 topics, same dataset as above, also running in Hadoop.
- freebase: Training a latent factor model on artist entities in the Freebase dump.
- plsa: Probabilistic Latent Semantic Analysis, using 40 factors and same dataset/framework as above. More factors give significantly better results, but still nothing that can compete with the other models.
Again, not all of these models are in production, and conversely, we have other algorithms not included above that are in production. This is just a selections of things we’ve experimented with. In particular, I think it’s interesting to note that neither PLSA nor LDA perform very well. Taking sequence into account (rnn, word2vec) seems to add a lot of value, but our best model (vector_exp) is a pure bag-of-words model.