Music recommendations using cover images (part 1)
Scrolling through the Discover page on Spotify the other day it occurred to me that the album is in fact a fairly strong visual proxy for what kind of content you can expect from it. I started wondering if the album cover can in fact be used for recommendations. For many obvious reasons this is a kind of ridiculous idea, but still interesting enough that I just had to explore it a bit. So, I embarked on a journey to see how far I could get in a few hours.
First thing I did was to scrape all album covers. We have a few million of them (I don’t think I could give you the exact number, or I would have to kill you). A full set of 64x64px images is 10 GB roughly, so not an insane amount.
 1024 random cover images in 16×16 px
1024 random cover images in 16×16 px
My first attempt at defining “similarity” was simply to resize all images to 16×16, convert to grayscale, subtract the mean and normalize by the variance. Each cover image is then essentially a 256-vector in Euclidean space. Load those vectors into Annoy and Bob’s your uncle! Nice!
These recommendations turn out to be pretty horrible, at best.
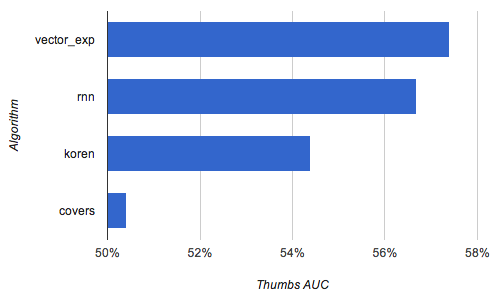 Classification score on predicting thumbs, measured by Area Under Curve (AUC). Random algorithm = 50%, higher numbers are better.
Classification score on predicting thumbs, measured by Area Under Curve (AUC). Random algorithm = 50%, higher numbers are better.
In the chart above, “covers” is the image-based method. “rnn” is recurrent neural networks, “koren” is this paper and “vector_exp” is a model I’ve described before.
This image similarity algorithm gave some fun results, like finding out that the most similar album to the left one was the right one:

In general, the only type of music I could reliably see this working on was minimal techno. Pretty much all minimal techno albums have a completely identical layout: a white (or light) circle on a black background:
 Most similar covers for Kassem Mosse – Workshop 12: http://open.spotify.com/album/0NQvm5y6CLtjtbyJNZltFg
Most similar covers for Kassem Mosse – Workshop 12: http://open.spotify.com/album/0NQvm5y6CLtjtbyJNZltFg
This wasn’t enough to resolve the question, so I kept searching for the answer. I stumbled across pyleargist by Oliver Grisel and to my delight it was trivial to install. Essentially pyleargist is a wrapper around a C library that takes any image and generates an image descriptor, which is a vector with 960 elements. Evaluating it using the same metric actually yields some fairly decent results:
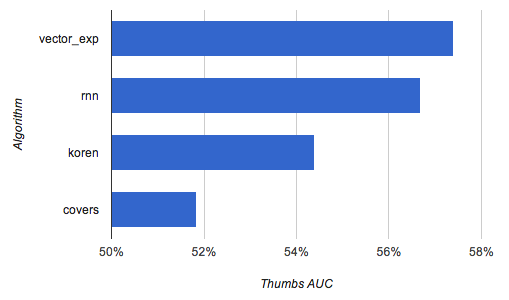 Classification score on predicting thumbs, measured by Area Under Curve (AUC). Random algorithm = 50%, higher numbers are better.
Classification score on predicting thumbs, measured by Area Under Curve (AUC). Random algorithm = 50%, higher numbers are better.
The results are already not that horrible (although with a very biased and quite unreliable metric). At least it’s definitely better than pure random.
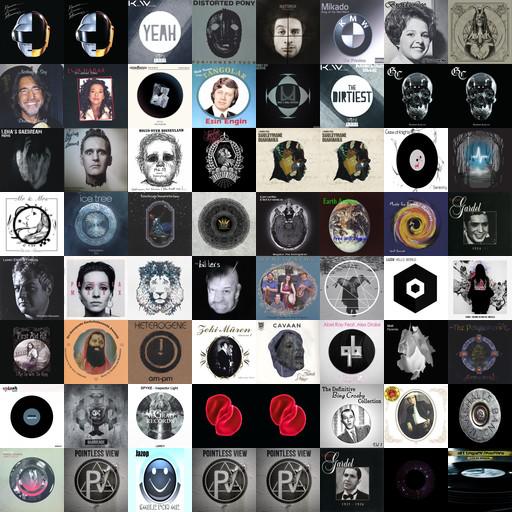 Most similar album covers to Daft Punk’s – Random Access Memories
Most similar album covers to Daft Punk’s – Random Access Memories
At this point I decided the next step on this journey of overengineering would be either, or possibly both out of
- Learning a mapping from image space to collaborative filtering space. That way we learn which features in the picture are relevant for the music. This is a similar idea to this paper.
- Venture into the realms of deep learning. I went to the Twitters for some assistance and got a ton of response back.
This is an ongoing project (and an ongoing source of frustrations) so I’ll defer the updates to a second part. Stay tuned!
Edit: Was linking to the wrong paper by Sander Dieleman’s paper!