The power of ensembles
From my presentation at MLConf, one of the points I think is worth stressing again is how extremely well combining different algorithms works.
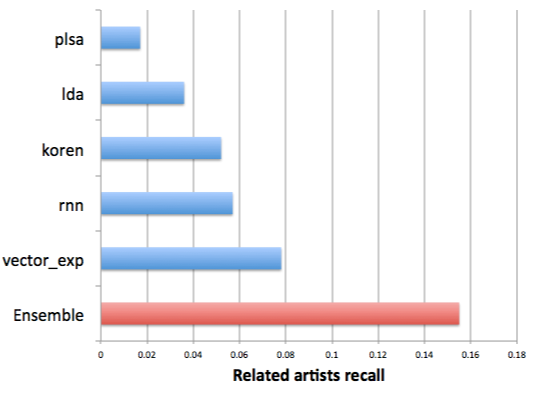
In this case, we’re training machine learning algorithms on different data sets (playlists, play counts, sessions) and different objectives (least squares, max likelihood). Then we combine all the models using gradient boosted decision trees training on a smaller but higher quality data set. Finally, we validate on a third data set, in this case looking at recall for a ground truth data set of related artists.
The ensemble was common knowledge throughout the Netflix prize, and the winner ended up having many hundreds of models in the ensemble. But measured in pure RMSE score the results weren’t mind blowing – the best models weren’t far from the best ensemble.
I think in a real world setting, chances are bigger that you have lots of models working on different data sets optimizing for different things. The bias of each model will be much larger, so the gains from combining all models are even larger.
Another difference in our case is we basically don’t know what to optimize for. There’s no single golden metric such as RMSE. Instead, we train things on different data sets. Eg individual models may be trained on playlists data, and the ensemble on thumbs. We then have a bunch of offline metrics as well as A/B test metrics we use to determine success.
Some people have suggested that these large ensembles are not practical and have tried to find a single good algorithm. I think this is a bad idea. Ensembles scale really well because you can parallelize all the work, and building a good framework it’s easy to add or remove new models. Data changes all the time and a good ensemble with a bunch of models makes recommendations robust and less sensitive to shift in the underlying data.
Our ensemble looks quite different (and much bigger) than the picture above. We are thinking a lot about adding diversified signals from various machine learning algorithms applied to different data sets. These signals can be anything from collaborative filtering to dummy things, content-based, or editorial data. Pretty much anything that can be converted into a numerical signal can be used.