I spent a couple of hours this weekend going through some pull requests and issues to Annoy, which is an open source C++/Python library for Approximate Nearest Neighbor search.
It’s still bizarre, but I probably deserved it, given how Annoy is abusing C++. The m->children array is declared as being only 2 elements long, but I deliberately overflow the array because I allocate extra space after it. I think this might cause GCC to unroll the loop to run twice.
I always feel a bit more comfortable when it turns out that the compiler is introducing bugs rather than my code. Made me think of the Jeff Dean joke: Jeff Dean builds his code before committing it, but only to check for compiler and linker bugs.
Anyway, after fixing this in three separately places, it seems like it’s finally working. Dirk Eddelbuettel is working on an R implementation of Annoy which is fun to see.
I haven’t spent much time with Annoy in a year or two and looking around it seems like there’s some new competitors on the block. Panns is one of them, another one is the LSHForest pull request for scikit-learn. I haven’t looked at them thoroughly, but they are both Python-only and claim some advantages over Annoy. None of them implement mmap as a method to load indexes, which imho is Annoy’s killer feature.
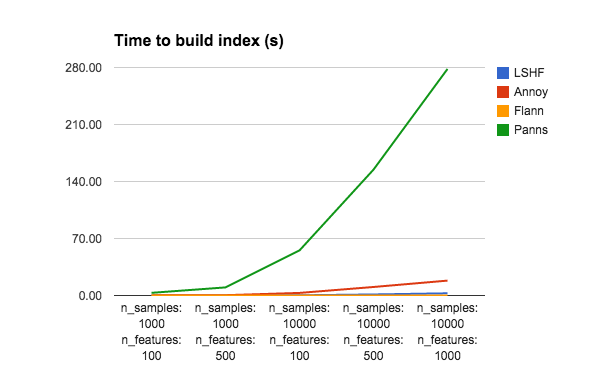
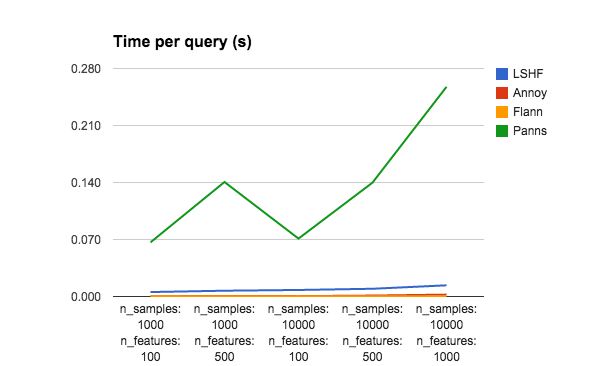
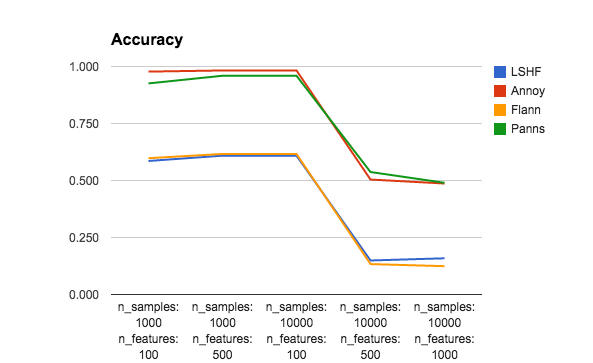
It’s extremely hard to compare all trade-offs between index building time, index size, query performance, and accuracy. So please don’t take this super seriously. The only thing I changed in the benchmark was (1) I added Panns, for good measure (2) I reduced the number of trees for Annoy (and Panns) to 10 instead of using n_features. Without reducing the number of trees for Annoy, it gets pretty much 100% accuracy for all data sets, but takes several minutes to build each index. So to emphasize approximate aspect of ANN, I decided to sacrifice some accuracy to gain performance.
Btw, I would love it if someone could help me reimplement the algo used by Panns in Annoy, since it seems pretty good.
|
|
<td data-sheets-value="[null,2,"Time building index (s)"]">
Time building index (s)
</td>
<td data-sheets-value="[null,2,"Average query time (ms)"]">
Average query time (ms)
</td>
<td data-sheets-value="[null,2,"Average accuracy"]">
Average accuracy
</td>
|
n_samples: 1000 n_features: 100
|
<td data-sheets-numberformat="[null,2,"0.000",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.000",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.000",1]">
</td>
|
LSHF
|
<td data-sheets-value="[null,3,null,0.0223457813263]" data-sheets-numberformat="[null,2,"0.00",1]">
0.02
</td>
<td data-sheets-value="[null,3,null,5.461249351499999]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
5.46
</td>
<td data-sheets-value="[null,3,null,0.5856]" data-sheets-numberformat="[null,2,"0.00",1]">
0.59
</td>
|
Annoy
|
<td data-sheets-value="[null,3,null,0.146422863007]" data-sheets-numberformat="[null,2,"0.00",1]">
0.15
</td>
<td data-sheets-value="[null,3,null,0.26562213897700004]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.27
</td>
<td data-sheets-value="[null,3,null,0.9776]" data-sheets-numberformat="[null,2,"0.00",1]">
0.98
</td>
|
Flann
|
<td data-sheets-value="[null,3,null,0.00321507453918]" data-sheets-numberformat="[null,2,"0.00",1]">
0.00
</td>
<td data-sheets-value="[null,3,null,0.17126083374]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.17
</td>
<td data-sheets-value="[null,3,null,0.5978]" data-sheets-numberformat="[null,2,"0.00",1]">
0.60
</td>
|
Panns
|
<td data-sheets-value="[null,3,null,3.27013206482]" data-sheets-numberformat="[null,2,"0.00",1]">
3.27
</td>
<td data-sheets-value="[null,3,null,66.48426055910001]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
66.48
</td>
<td data-sheets-value="[null,3,null,0.9258]" data-sheets-numberformat="[null,2,"0.00",1]">
0.93
</td>
|
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
n_samples: 1000 n_features: 500
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
LSHF
|
<td data-sheets-value="[null,3,null,0.0957989692688]" data-sheets-numberformat="[null,2,"0.00",1]">
0.10
</td>
<td data-sheets-value="[null,3,null,7.10513591766]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
7.11
</td>
<td data-sheets-value="[null,3,null,0.609]" data-sheets-numberformat="[null,2,"0.00",1]">
0.61
</td>
|
Annoy
|
<td data-sheets-value="[null,3,null,0.388671875]" data-sheets-numberformat="[null,2,"0.00",1]">
0.39
</td>
<td data-sheets-value="[null,3,null,0.7512760162350001]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.75
</td>
<td data-sheets-value="[null,3,null,0.9826]" data-sheets-numberformat="[null,2,"0.00",1]">
0.98
</td>
|
Flann
|
<td data-sheets-value="[null,3,null,0.00826096534729]" data-sheets-numberformat="[null,2,"0.00",1]">
0.01
</td>
<td data-sheets-value="[null,3,null,0.24263381958]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.24
</td>
<td data-sheets-value="[null,3,null,0.6164]" data-sheets-numberformat="[null,2,"0.00",1]">
0.62
</td>
|
Panns
|
<td data-sheets-value="[null,3,null,9.94446802139]" data-sheets-numberformat="[null,2,"0.00",1]">
9.94
</td>
<td data-sheets-value="[null,3,null,140.598635674]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
140.60
</td>
<td data-sheets-value="[null,3,null,0.9594]" data-sheets-numberformat="[null,2,"0.00",1]">
0.96
</td>
|
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
n_samples: 10000 n_features: 100
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
LSHF
|
<td data-sheets-value="[null,3,null,0.247771978378]" data-sheets-numberformat="[null,2,"0.00",1]">
0.25
</td>
<td data-sheets-value="[null,3,null,8.01199913025]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
8.01
</td>
<td data-sheets-value="[null,3,null,0.609]" data-sheets-numberformat="[null,2,"0.00",1]">
0.61
</td>
|
Annoy
|
<td data-sheets-value="[null,3,null,3.16764092445]" data-sheets-numberformat="[null,2,"0.00",1]">
3.17
</td>
<td data-sheets-value="[null,3,null,0.44639110565199996]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.45
</td>
<td data-sheets-value="[null,3,null,0.9826]" data-sheets-numberformat="[null,2,"0.00",1]">
0.98
</td>
|
Flann
|
<td data-sheets-value="[null,3,null,0.0239078998566]" data-sheets-numberformat="[null,2,"0.00",1]">
0.02
</td>
<td data-sheets-value="[null,3,null,0.203204154968]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.20
</td>
<td data-sheets-value="[null,3,null,0.6164]" data-sheets-numberformat="[null,2,"0.00",1]">
0.62
</td>
|
Panns
|
<td data-sheets-value="[null,3,null,55.3448691368]" data-sheets-numberformat="[null,2,"0.00",1]">
55.34
</td>
<td data-sheets-value="[null,3,null,71.1174964905]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
71.12
</td>
<td data-sheets-value="[null,3,null,0.9594]" data-sheets-numberformat="[null,2,"0.00",1]">
0.96
</td>
|
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
n_samples: 10000 n_features: 500
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
LSHF
|
<td data-sheets-value="[null,3,null,1.28864502907]" data-sheets-numberformat="[null,2,"0.00",1]">
1.29
</td>
<td data-sheets-value="[null,3,null,9.49889659882]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
9.50
</td>
<td data-sheets-value="[null,3,null,0.1492]" data-sheets-numberformat="[null,2,"0.00",1]">
0.15
</td>
|
Annoy
|
<td data-sheets-value="[null,3,null,10.4567909241]" data-sheets-numberformat="[null,2,"0.00",1]">
10.46
</td>
<td data-sheets-value="[null,3,null,1.1410522460899999]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
1.14
</td>
<td data-sheets-value="[null,3,null,0.5042]" data-sheets-numberformat="[null,2,"0.00",1]">
0.50
</td>
|
Flann
|
<td data-sheets-value="[null,3,null,0.0745980739594]" data-sheets-numberformat="[null,2,"0.00",1]">
0.07
</td>
<td data-sheets-value="[null,3,null,0.243935585022]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.24
</td>
<td data-sheets-value="[null,3,null,0.1334]" data-sheets-numberformat="[null,2,"0.00",1]">
0.13
</td>
|
Panns
|
<td data-sheets-value="[null,3,null,154.577830076]" data-sheets-numberformat="[null,2,"0.00",1]">
154.58
</td>
<td data-sheets-value="[null,3,null,139.825344086]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
139.83
</td>
<td data-sheets-value="[null,3,null,0.5372]" data-sheets-numberformat="[null,2,"0.00",1]">
0.54
</td>
|
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
n_samples: 10000 n_features: 1000
|
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
<td data-sheets-numberformat="[null,2,"0.00",1]">
</td>
|
LSHF
|
<td data-sheets-value="[null,3,null,2.69871807098]" data-sheets-numberformat="[null,2,"0.00",1]">
2.70
</td>
<td data-sheets-value="[null,3,null,13.7353038788]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
13.74
</td>
<td data-sheets-value="[null,3,null,0.1588]" data-sheets-numberformat="[null,2,"0.00",1]">
0.16
</td>
|
Annoy
|
<td data-sheets-value="[null,3,null,18.2781989574]" data-sheets-numberformat="[null,2,"0.00",1]">
18.28
</td>
<td data-sheets-value="[null,3,null,2.32357978821]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
2.32
</td>
<td data-sheets-value="[null,3,null,0.4868]" data-sheets-numberformat="[null,2,"0.00",1]">
0.49
</td>
|
Flann
|
<td data-sheets-value="[null,3,null,0.11420583725]" data-sheets-numberformat="[null,2,"0.00",1]">
0.11
</td>
<td data-sheets-value="[null,3,null,0.322947502136]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
0.32
</td>
<td data-sheets-value="[null,3,null,0.1242]" data-sheets-numberformat="[null,2,"0.00",1]">
0.12
</td>
|
Panns
|
<td data-sheets-value="[null,3,null,278.210582972]" data-sheets-numberformat="[null,2,"0.00",1]">
278.21
</td>
<td data-sheets-value="[null,3,null,257.453641891]" data-sheets-numberformat="[null,2,"0.00",1]" data-sheets-formula="=R[-32]C[0]*1000">
257.45
</td>
<td data-sheets-value="[null,3,null,0.49]" data-sheets-numberformat="[null,2,"0.00",1]">
0.49
</td>