Norvig's claim that programming competitions correlate negatively with being good on the job
I saw a bunch of tweets over the weekend about Peter Norvig claiming there’s a negative correlation between being good at programming competitions and being good at the job. There were some decent Hacker News comments on it.
Norvig’s statement is obviously not true if we’re drawing samples from the general population – most people can’t code. It doesn’t necessarily even have to do with time allocation as this commenter alluded to:
Being a champion at something requires excruciating narrow focus on something for unusually long time. If you are getting GPA of 4.0 or play Rachmaninoff’s Piano Concerto No 3 or deadlift 400 pounds or in top 1000 chess players – you probably have to work on it for hours a day for years while ignoring everything else (of course unless you are one of those 1 in million polymath).
Here’s the real reason: Google is already selecting for the top 1% programmers using some criteria, leading to selection bias. Even if the two values are positively correlated, you might have a selection criterion that leads to a negative correlation.
But let’s start with the ideal case. Let’s say there’s a slight positive correlation between “being good at programming competitions” and “what really matters”. Let’s assume Google hires perfectly. Let’s assume everyone is on a multivariate Gaussian:
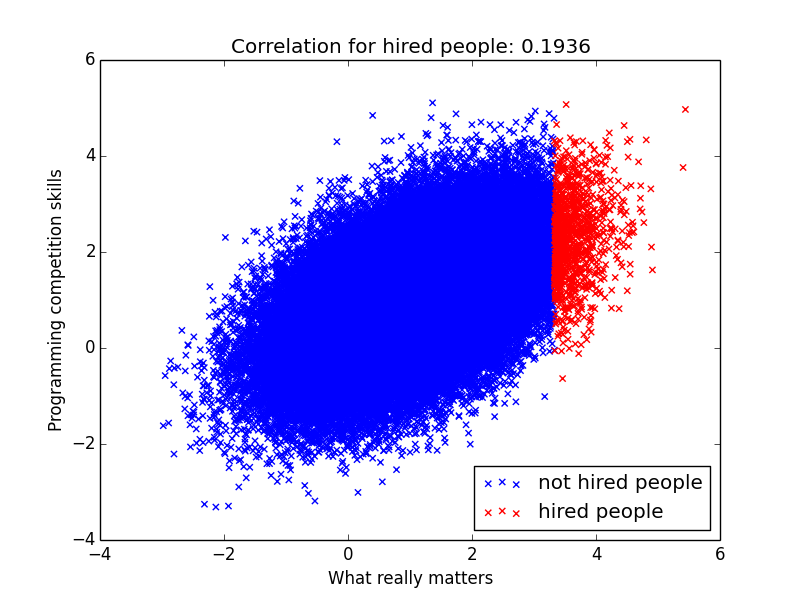
For all the people that were hired, I calculate the correlation between “Programming competition skills” and “What really matter”. The correlation for hired people is almost 0.2 and it’s still positive!
However let’s say Google for some reason puts too much weight on programming competitions during the interviews. We now get a negative correlation!
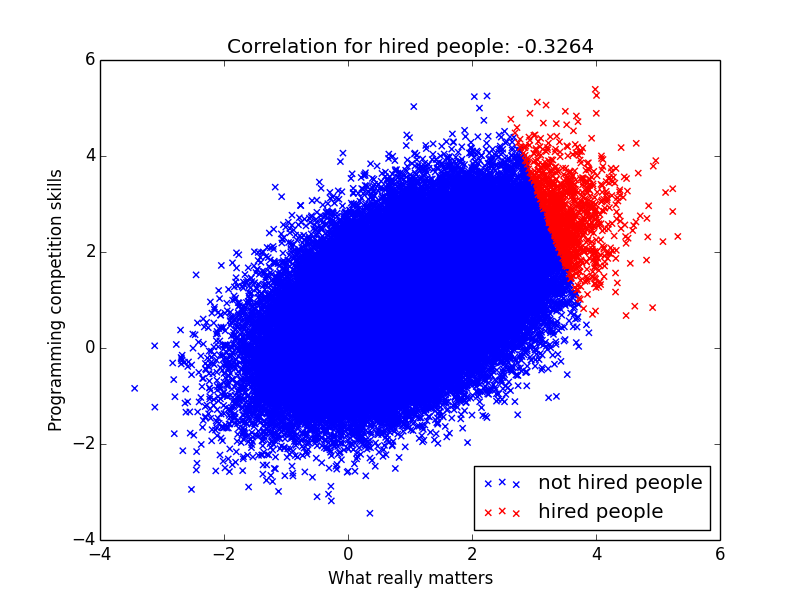
Does this mean it’s bad to hire people who are good at programming competition? No, it just means that we probably overweighted it during the hiring process. If we lower the weight a bit we get something a positive correlation again:
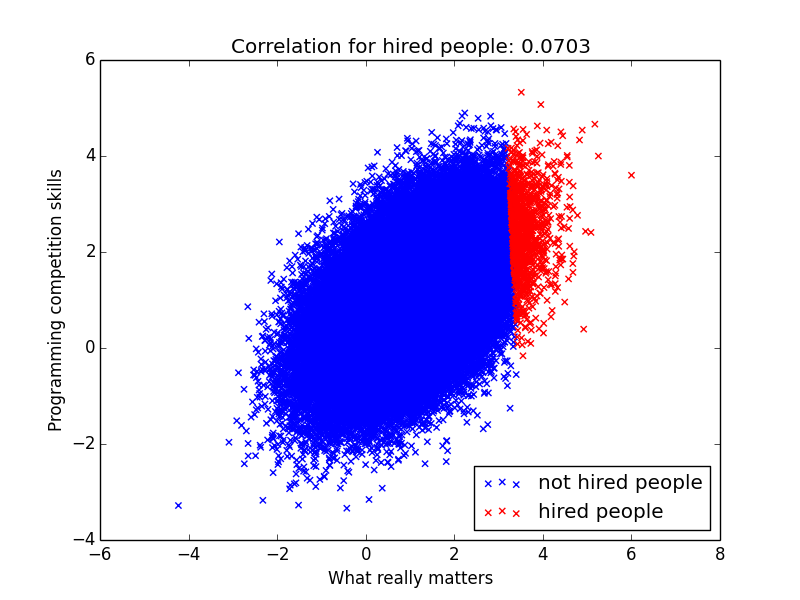
But in general does it mean we should never look at programming competition skills? Actually the reality is a lot more complicated. Instead of observing what really matters, you observe some crappy proxy for it. And when all metrics is noisy, you should put some nonzero positive weight on any metric that correlate positively with your target. Just not too much!
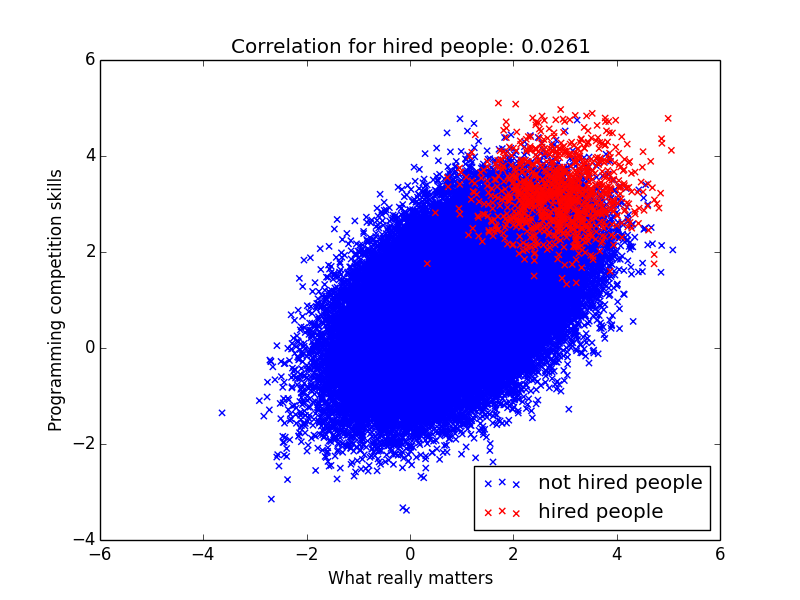
Sorry for spamming you with scatter plots, but it’s in the name of statistics! My point here is that you can tweak these variables and end up seeing correlations with pretty much any value. So when you have these complex selection biases you need to be super careful about how to interpret the data. It’s a great reminder that studies like Project Oxygen always need to be taken with a bucket of sea salt.
Are there other examples of selection biases leading to spurious correlations? Let me know!
Tagged with: hiring, math