Better precision and faster index building in Annoy
Sometimes you have these awesome insights. A few days ago I got an idea for how to improve index building in Annoy.
For anyone who isn’t acquainted with Annoy – it’s a C++ library with Python bindings that provides fast high-dimensional nearest neighbor search.
Annoy recursively builds up a tree given a set of points. The algorithm so far was: at every level, pick a random hyperplane out of all possible hyperplanes that intersect the convex hull given by the point set. The hyperplane defines a way to split the set of points into two subsets. Recursively apply the same algorithm on each subset until there’s only a small set of points left.
A much smarter way is this: sample two points from the set of points, compute the hyperplane equidistant to those points, and use this hyperplane to split the point set.
(I just described what happens for Euclidean distance. Angular is almost the same, just slightly simpler).
Implementing this turns makes index building 4x faster for Euclidean distance. But more importantly, the search quality is substantially better, both for angular and Euclidean distance. The difference is particularly large for high dimensional spaces.
I put together a test that measures precision for nearest neighbor search on the GloVe pretrained vectors using some hardcoded values for various parameters (10 trees, 10 nearest neighbors). See below:
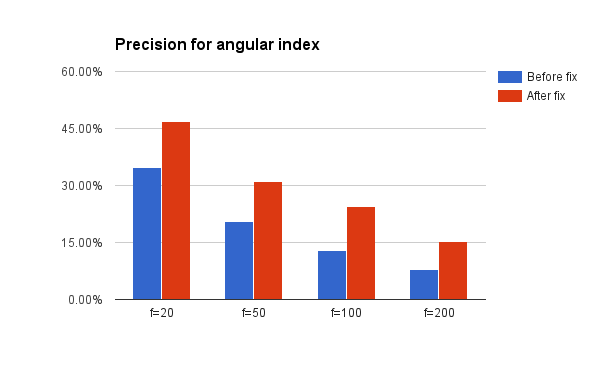
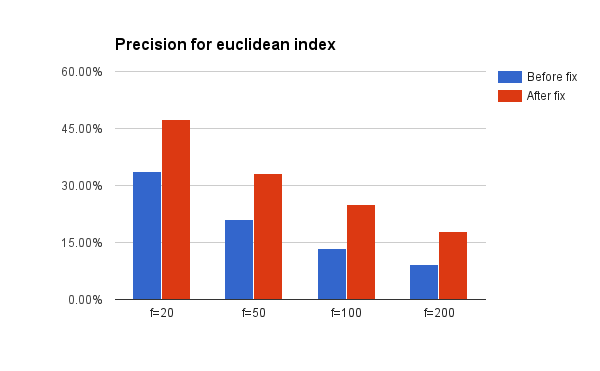
This is pretty cool given that the commit is actually more red than green – the new algorithm is a lot simpler and I could remove a lot of old stuff that was no longer needed.
The intuitive reason why this works so well is: consider what happens if you have 200 dimensions, but your data is really “mostly” located on a lower dimensional space of say 20 dimensions. Then Annoy will find splits that are more aligned with the distribution of your data. I suspect these cases are pretty common in high dimensional spaces.
I also fixed another randomness issue that looked pretty severe (although I think in practice it didn’t cause any issues) and added a unit tests that runs the f=25 test shown above in the graphs.
There is a fresh 1.3.1 version out on PyPI and Github – get it while it’s hot!
Tagged with: approximate nearest neighbors