Benchmark of Approximate Nearest Neighbor libraries
Annoy is a library written by me that supports fast approximate nearest neighbor queries. Say you have a high (1-1000) dimensional space with points in it, and you want to find the nearest neighbors to some point. Annoy gives you a way to do this very quickly. It could be points on a map, but also word vectors in a latent semantic representation or latent item vectors in collaborative filtering.
I’ve made a few optimizations to Annoy lately and I was curious to see how it stacks up against other libraries out there, so I wrote a benchmark suite: ann-benchmarks. It supports any library with a Python interface and I added a bunch of them. It even has Travis integration!
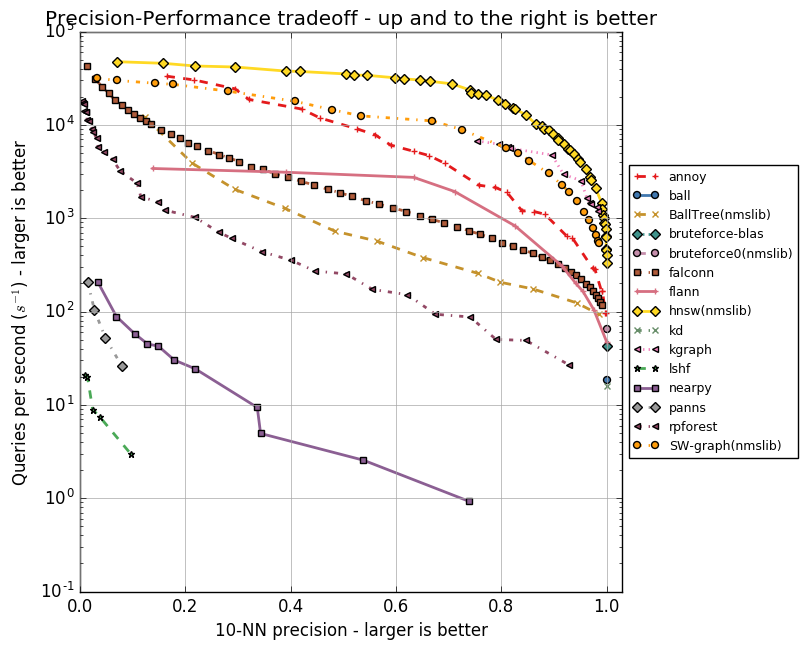
Cosine 100D results
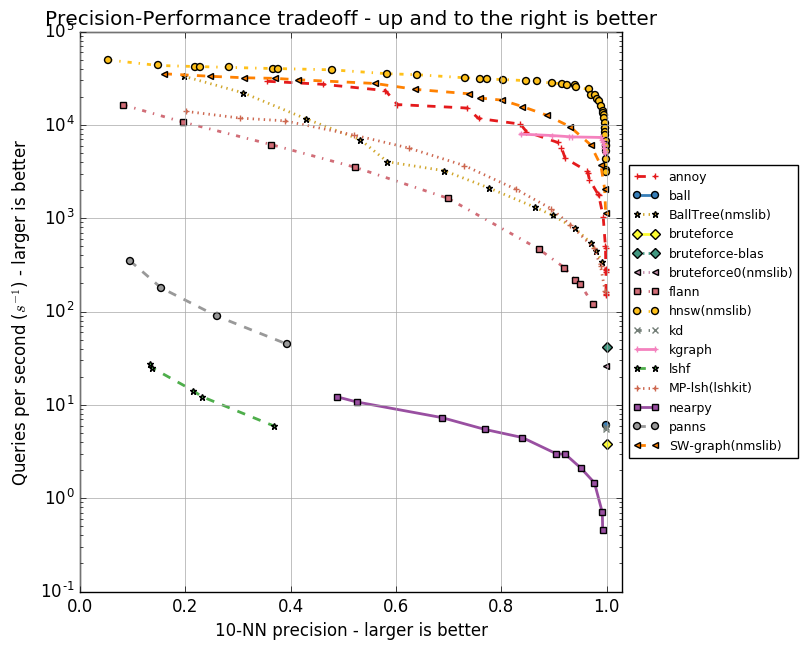
Results for 128D Euclidean
The results so far for Annoy are pretty great. The only method that consistently beats Annoy is SW-graph from nmslib which is about 2-3x faster at the same precision. But Annoy beats both FLANN and KGraph at high precisions (>95%). At lower precisions (<95%) and cosine distance, Annoy is not quite as fast as FLANN and KGraph.
A surprising result was that Panns, Nearpy, and LSHForest all are very low performance. They are roughly 1,000 times slower than the other ones, and even worse, Panns & LSHForest don’t even produce high precision scores. I created an issue in scikit-learn about LSHForest’s performance. Of course, it might be that I did something wrong in the benchmark.
Annoy was actually never built with performance in mind. The killer feature was always to be able to load/unload indexes quickly using mmap – which no other package supports – but it’s fun to see that it’s actually very competitive on performance too. One of the things that made a difference was that I recently changed the interface for Annoy slightly (don’t worry, it’s backwards compatible). There is now a query-time tradeoff knob which lets you vary how many nodes are inspected.
The other factor not covered by the graph above is how hard it is to install most of these libraries. Annoy should compile and run almost anywhere (Linux, Win, OS X) very easily, but the other libraries can be challenging to install. For instance, both kgraph and nmslib depend on GCC-4.8, so they require custom installations. There are scripts to install all libraries in the repo tested with Ubuntu 12.04 and 14.04. For other platforms – good luck!
I might do a talk in September at the NYC Machine Learning meetup about this, we’ll see! Until then, I found this really great presentation by Stefan Savev (with corresponding web site). He claims his own implementation is a bit faster than Annoy! It’s in Scala so I haven’t tested it yet.
Slides from Stefan Savev’s presentation
Tagged with: approximate nearest neighbors