More MCMC – Analyzing a small dataset with 1-5 ratings
I’ve been obsessed with how to iterate quickly based on small scale feedback lately. One awesome website I encountered is Usability Hub which lets you run 5 second tests. Users see your site for 5 seconds and you can ask them free-form questions afterwards. The nice thing is you don’t even have to build the site – just upload a static png/jpg and collect data.
We are redesigning our website, so I ran a bunch of experiments where I asked users how trustworthy they think the website looks like, on a scale from 1 to 5. So let’s say you do that for several variants. How do you estimate the uncertainty of the average score?
You could compute the mean and the variance and use that to estimate. But let’s pause for a second. We know this distribution is not a normal distribution because it’s constrained to integers between 1 and 5.
Instead, let’s use a multinomial distribution for the distributions of the five possible ratings. Furthermore let’s say prior distribution is a Dirichlet distribution. Now let’s compute the weighted average using the posterior of the that distribution. Much cooler!
I also discovered PyMC3 and Seaborn which turns out to be two pretty cool tools. Relevant code:
Output:
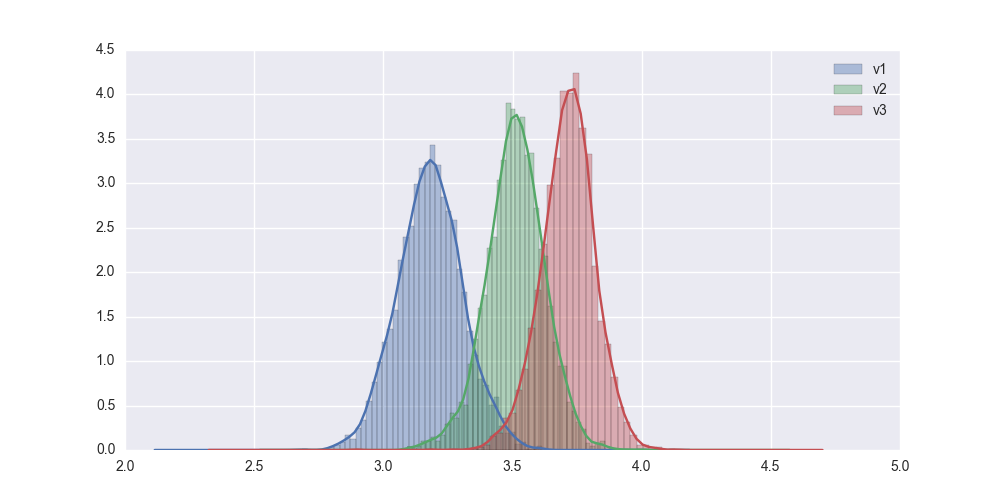 Beautiful stuff! But how does it compare to the normal approximation? I’m glad you asked! Here are both on the same plot:
Beautiful stuff! But how does it compare to the normal approximation? I’m glad you asked! Here are both on the same plot:
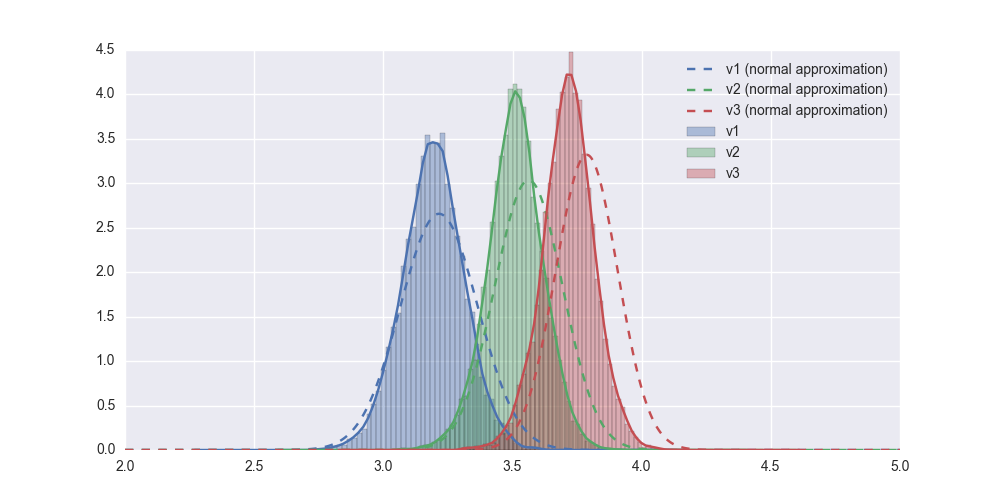
You can see that there is a substantial difference. This is caused by two things: (a) our sample is not drawn from a normal distribution (b) the sample size is small.
For large sample sizes, the average of non-normal distributions converges to have a normal distribution (this is the Central limit theorem), but our sample size is very small (only 50 ratings in each set).
Dealing with these small dataset reminds me of the discussion between Karl Pearson and William Sealy Gossett (aka Student). Gossett, working for the Guinness factory in Dublin, developed a lot of modern statistics working with beer samples, in particular with small batch sizes. Talking to Pearson about this, Pearson remarked that Only naughty brewers deal in small samples! The t-test (of Gossett) is a great example of something coming out of necessity of working with small samples sizes. For larger samples, normal approximations work out very well.
Side note: I found a discussion by Andrew Gelman suggesting modeling this as a softmax instead – another option worth trying if you’re interested)
Tagged with: statistics