New benchmarks for approximate nearest neighbors
UPDATE(2018-06-17): There are is a later blog post with newer benchmarks!
One of my super nerdy interests include approximate algorithms for nearest neighbors in high-dimensional spaces. The problem is simple. You have say 1M points in some high-dimensional space. Now given a query point, can you find the nearest points out of the 1M set? Doing this fast turns out to be tricky.
I’m the author of Annoy which has more than 3,000 stars on Github. Spotify used a lot of vector spaces models for music recommendations, and I think as people embrace vector space models more and more, we’ll see more attention to fast approximate searches.
What’s bothered me about the research is that there’s a thousand papers about how to do this, but very little empirical comparison. I built ANN-benchmarks to address this. It pits a bunch of implementations (including Annoy) against each other in a death match: which one can return the most accurate nearest neighbors in the fastest time possible. It’s not a new project, but I haven’t actively worked on it for a while.
Recently, two researchers (Martin Aumüller and Alexander Faithfull) published a paper featuring ANN-benchmarks and were nice enough to include me as a co-author (despite not writing a single word in the paper). They contributed a ton of useful stuff into ANN-benchmarks which made me realize that my tool could be some kind of “golden standard” for all approximate nearest neighbor benchmarking going forward. So I decided to spend a bit more time making ANN-benchmarks ridiculously easy to use for researchers or industry practitioners active in this field.
My hope is that there is a group of people who care about approximate nearest neighbor search, and hopefully people everyone can stick to the same benchmarks going forward. That would be great, because it makes everyone’s lives easier (kind of like how ImageNet made it easier for the deep learning crowd).
What’s new in ANN-benchmarks?
What are the things I’ve added in the last few months? A bunch of stuff:
- All algorithms are now Dockerized. This means you don’t have to install a bunch of stuff on the host computer, and deal with all the mess that that entails. All you need to do to add a new algorithm is to create a Dockerfile and some more config. Very nice!
- It comes with pre-computed datasets. I’ve collected a bunch of different vector datasets (MNIST and many other ones), split in train and test sets, and computed the nearest neighbors for the test set. Everyone can just download the dataset and use it.
- I finally got the Travis-CI test working kind of (it’s still a bit flaky).
I re-ran all benchmarks, which took a few days and about $100 in EC2 costs. The results depend on what dataset you use, but are somewhat consistent. I’m not going to get into the details. All you need to know for now is that the further up and to the right is better. Feel free to check out ANN-benchmarks for more info.
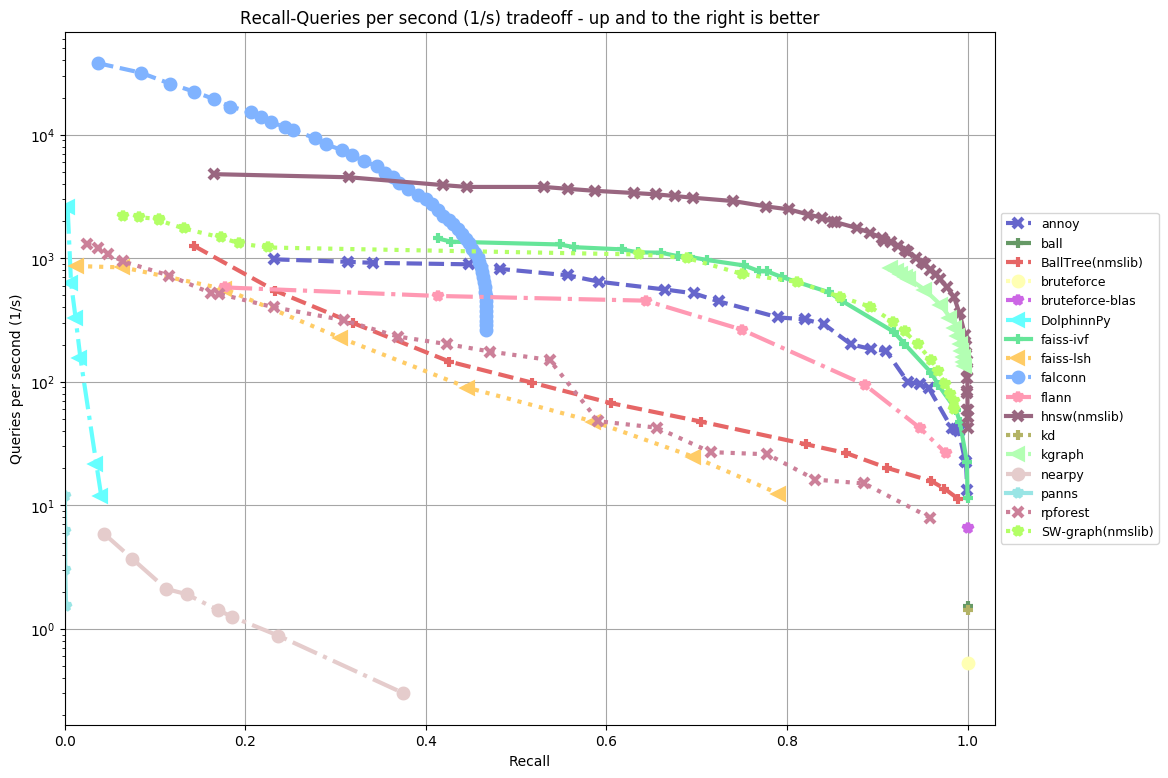
glove-100-angular:
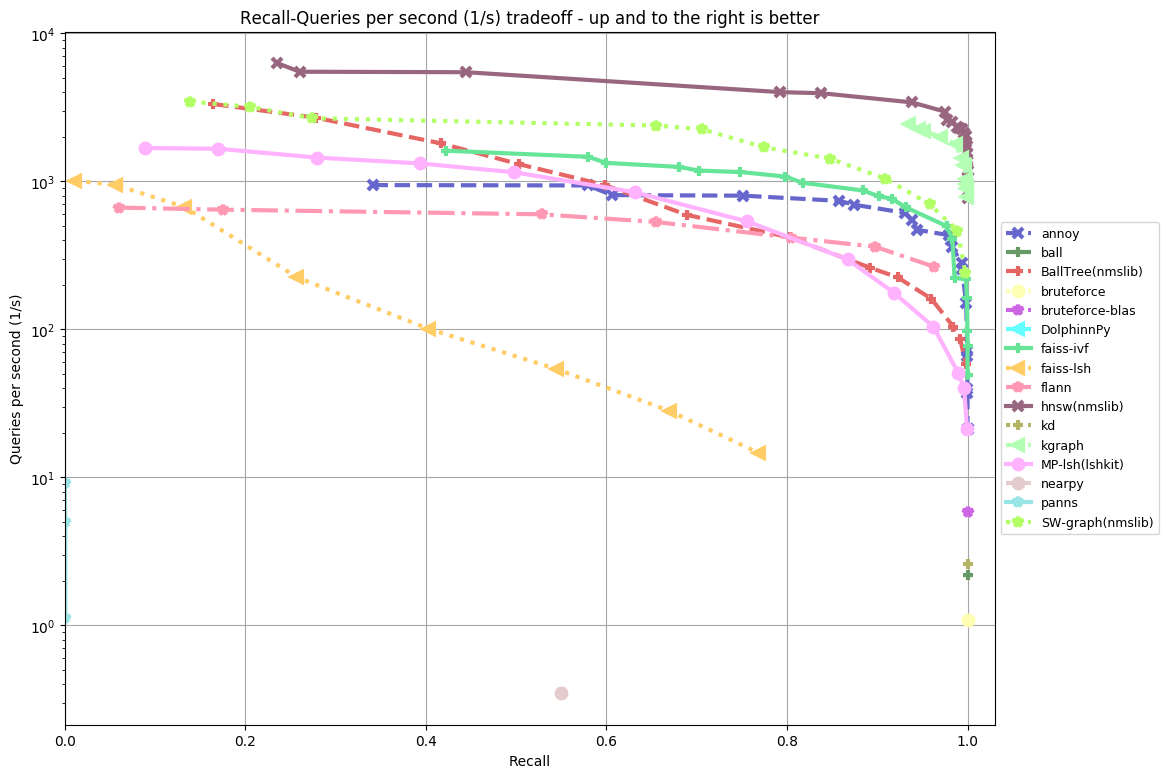
sift-128-euclidean:
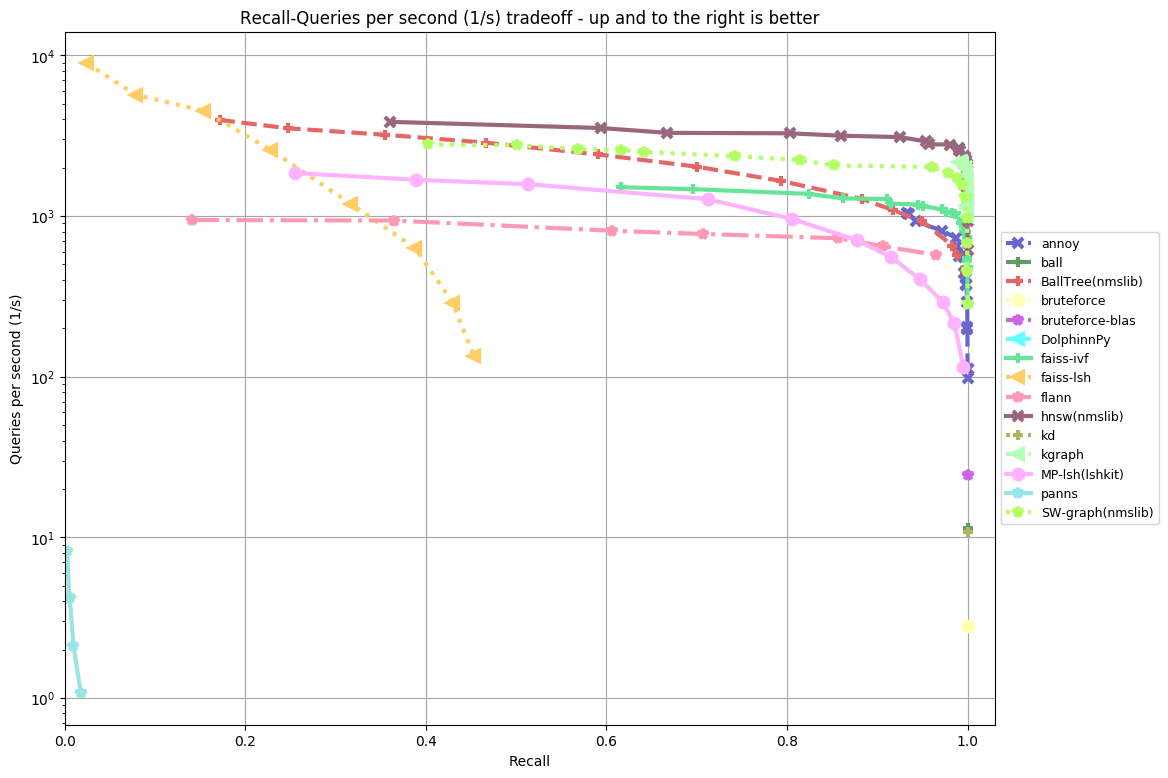
fashion-mnist-784-euclidean:
gist-960-euclidean:
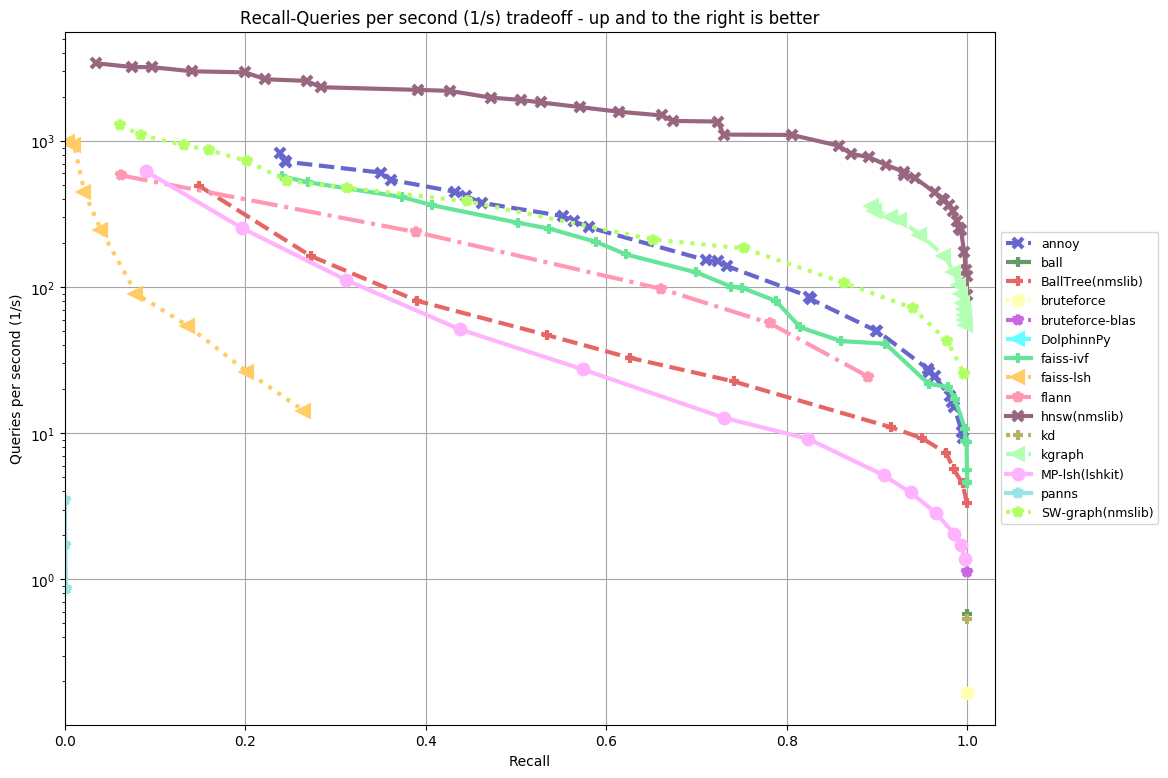
In almost all the datasets the top 5 are in the following order:
- HNSW (hierarchical navigable small world) from NMSLIB (non metric search library) knocks it out of the park. It’s over 10x faster than Annoy.
- KGraph is not far behind, which is another graph-based algorithm
- SW-graph from NMSLIB
- FAISS-IVF from FAISS (from Facebook)
- Annoy (I wish it was a bit faster, but think this is still honorable!)
In previous benchmarks, FALCONN used to perform very well, but I’m not sure what’s up with the latest benchmarks – seems like a huge regression. If any of the authors are reading this, I’d love it if you can figure out what’s going on. FALCONN somewhat interesting because it’s the the only library I’ve seen that gets decent results using locality sensitive hashing. Other than that, I haven’t been very impressed by LSH. Graph-based algorithms seem be the state of the art, in particular HNSW. Annoy uses a very different algorithms (recursively partitions the space using a two-means algorithm).
A final word
Going forward, if I see a paper about fast approximate nearest neighbor queries, and it doesn’t include proper benchmarks against any of the top libraries, I’m not going to give a 💩! ANN-benchmarks makes it too easy not to have an excuse for it!
Tagged with: machine learning, approximate nearest neighbors