Storm in the stratosphere: how the cloud will be reshuffled
Here’s a theory I have about cloud vendors (AWS, Azure, GCP):
- Cloud vendors1 will increasingly focus on the lowest layers in the stack: basically leasing capacity in their data centers through an API.
- Other pure-software providers will build all the stuff on top of it. Databases, running code, you name it.
We currently have cloud vendors that offer end-to-end solutions from the developer experience down to the hardware:

What if cloud vendors focus on the lowest layer, and other (pure software) vendors on the layer above?

Feel free to bring this up in five years to make me embarrassed about how wrong I turned out to be. But let me walk you through my thinking—I think some of it is quite well illustrated through the story of Redshift.
Redshift and what happened
Redshift is a data warehouse (aka OLAP database) offered by AWS. Before Redshift, it was the dark ages. The main player was Teradata, which had an on-prem offering. Startups said no to SQL and used Hadoop—SQL was kind of lame back then, for reasons that in hindsight appear absurd. I’m very happy we’re out of this era.
Anyway, one vendor was a company called ParAccel. AWS licensed their technology, rebranded it Redshift, and launched in 2012.
Redshift at the time was the first data warehouse running in the cloud. It was a brilliant move by AWS, because it immediately lowered the bar for a small company to start doing analytics. You didn’t have to set up any infrastructure yourself, or write custom mapreduce and reload the jobtracker all day. You could spin up a Redshift cluster in AWS, feed it humongous amounts of data, and it would … sort of just work.
Enter Snowflake
Snowflake2 is a $100B+ publicly traded company. Basically their entire offering is a data warehouse that looks fairly similar to Redshift.3
If you looked at Redshift in 2012, there was a lot of things that favored it. AWS had large economies of scale, had control of the underlying substrate (EC2), and could make larger investments in building the software. Maybe because of the value of lock-in, they could even subsidize the development of Redshift and make up the money through other products. Anyway, this is what it looks like nine years later4:
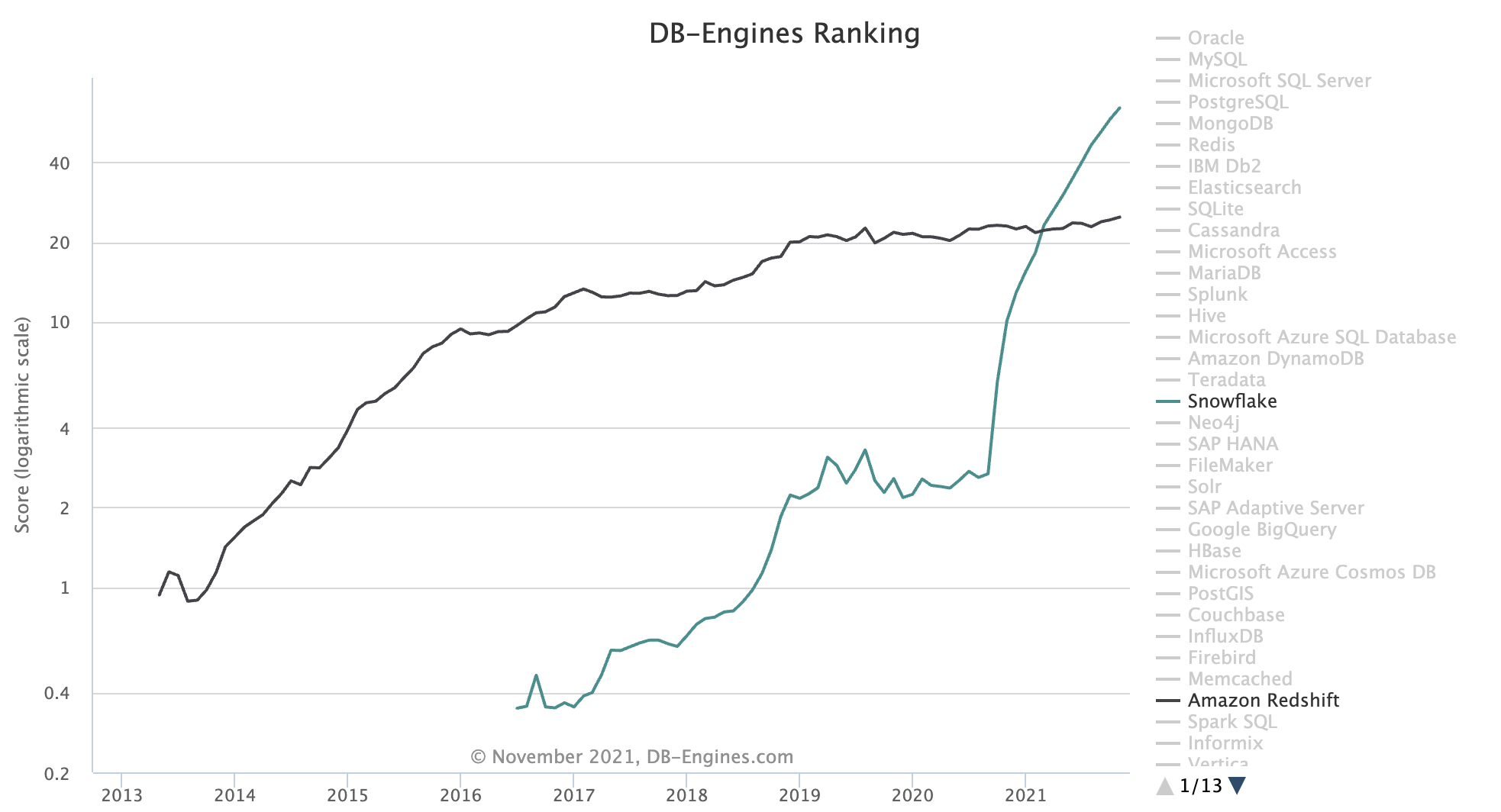
What happened? But my more general question is: what are the forces that favor a company like Snowflake?5 And what does that mean for other cloud products?
What if….?
There’s some sort of folk wisdom that the lowest layer of cloud services is a pure commodity service. So in order to make money you need to do at least one of:
- Make money higher up in the stack.
- Use services higher up in the stack to lock customers in. Then make money lower in the stack.
I think there’s some truth to these, at least looking historically, but there are some interesting trends blowing in the other way:
- The “software layer on top” is getting incredibly competitive. There’s so many startups going after it, fueled by cheap VC money and willing to burn billions of dollars on building software.
- Cloud vendors might be pretty happy making money just in the lowest layer. Margins aren’t so bad and vendor lock-in is still pretty high.
Startups are coming for the cloud
There’s never been this many companies going after services that traditionally belonged to the cloud vendors:
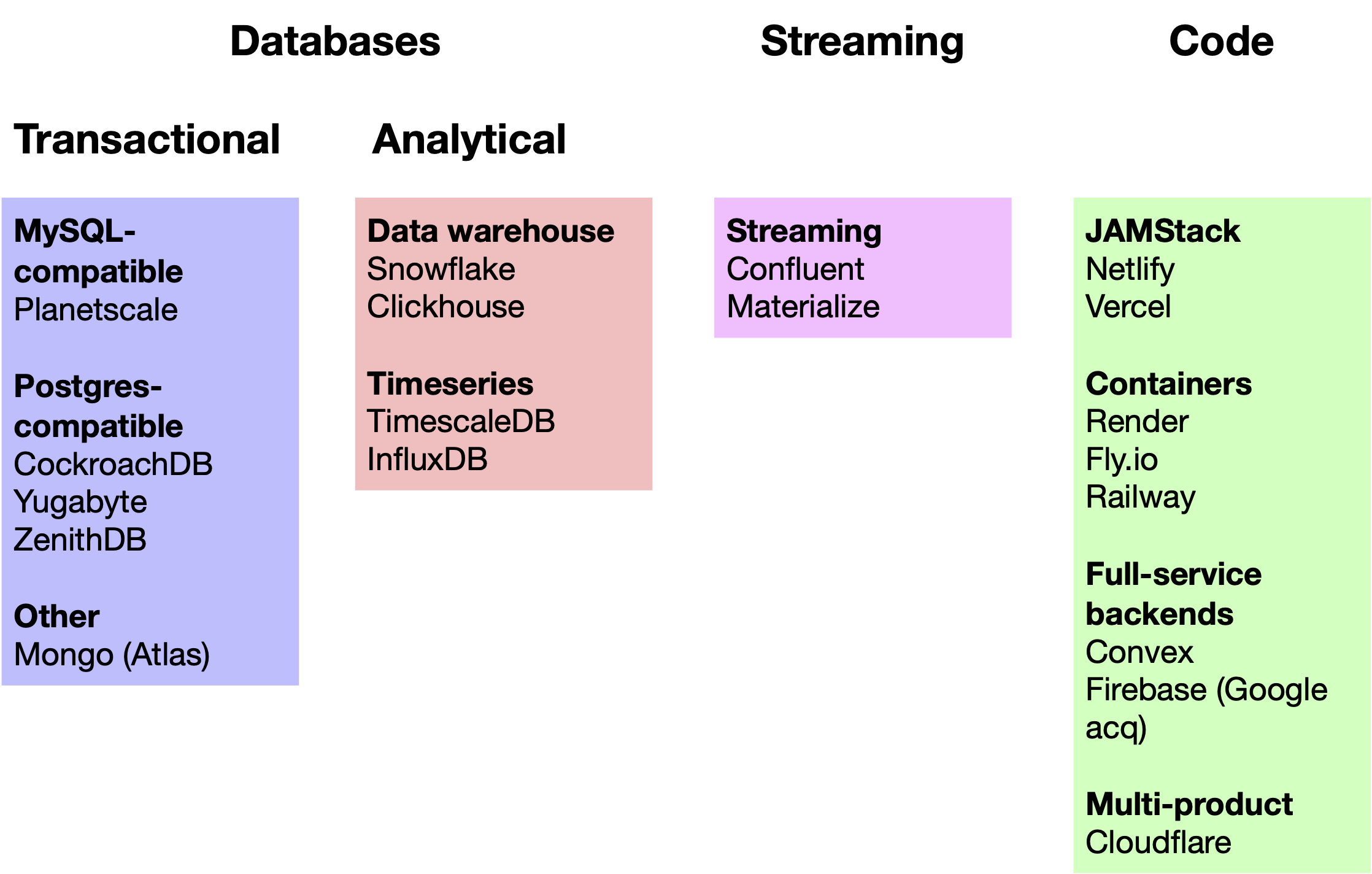
What’s going on? Probably a confluence of a lot of things. If I was tired, I would just shrug and say something like “startup circle of life, whatever”. And I think this is roughly one factor, but I see at least 3 different ones:
- Incentives at big companies often makes it hard to ship new crazy ideas. At the same time, VCs are pouring in money into the segment. If you’re an ambitious person, do you go work at AWS? Or do you join an early stage startup, or create your own? It’s expected that innovation shifts away from big companies to startups.
- Software vendors can build for all the cloud vendors at the same time. I think this was a real benefit for Snowflake, since a lot of their early customers were banks who care about multi-cloud, but more generally it also expands the market size vs the reach of any cloud vendor.
- A lot of the successful cloud products started out as internal services. This has been an amazing source of products, that have been battle-tested at Amazon, Google, and Microsoft scale, and it makes sense that those tools are a great match for their big enterprise customers. But the flipside of the extreme focus on scale, reliability, and configurability, is that the developer experience has become an attack vector, in particular when you look at mid-market and smaller customers who may care more about improving developer productivity. Slightly larger companies like Uber, Netflix, and Airbnb have a history of teams leaving to commercialize internal tools (often through the intermediate step of open sourcing it). Somewhat subjectively and anecdotally, these tools tend to have a much higher focus on developer experience.
Maybe owning the lowest layer isn’t so bad?
Let’s say a customer is spending $1M/year on Redshift. That nets AWS about6 $500-700k in gross profits, after paying for EC2 operational cost and depreciation. If that customer switches their $1M/year budget to Snowflake, then about $400k7 goes back to AWS, making AWS about $200k in gross profits.
That seems kind of bad for AWS? I don’t know, we ignored a bunch of stuff here. Snowflake’s projected8 2022 research and development costs are 20% of revenue, and their sales and marketing costs are 48%! For a million bucks revenue, that’s $700k. Translated back to AWS, maybe AWS would have spent $300-400k for the same thing? Seems reasonable.
Now the math suddenly adds up to me. AWS basically ends up with the same bottom line impact, but effectively “outsources” to Snowflake all the cost of building software and selling it. That seems like a good deal for them!
What about lock-in?
The other argument for why AWS should build their own software services is that it increases lock-in. So maybe Redshift in itself isn’t a cash cow, but it decreases the churn on EC2.
I’m not so sure? I spent six years as a CTO and moving from one cloud to another isn’t something I even remotely considered. My company, like most, spent far more money on engineer salaries than the cloud itself. Putting precious eng time on a cloud migration isn’t worth it unless cloud spend starts to become a significant fraction of your gross margins. Which is true for some companies! But those are in a minority.
A significant factor in all of this is that existing infra provides significant “gravity”. It’s not like you can just pick whichever cloud vendor has the cheapest database and run your DB there. You want to run things in the same cloud provider9 and in the same data center10. Looking at sign-up flows for cloud products gives us a hint:
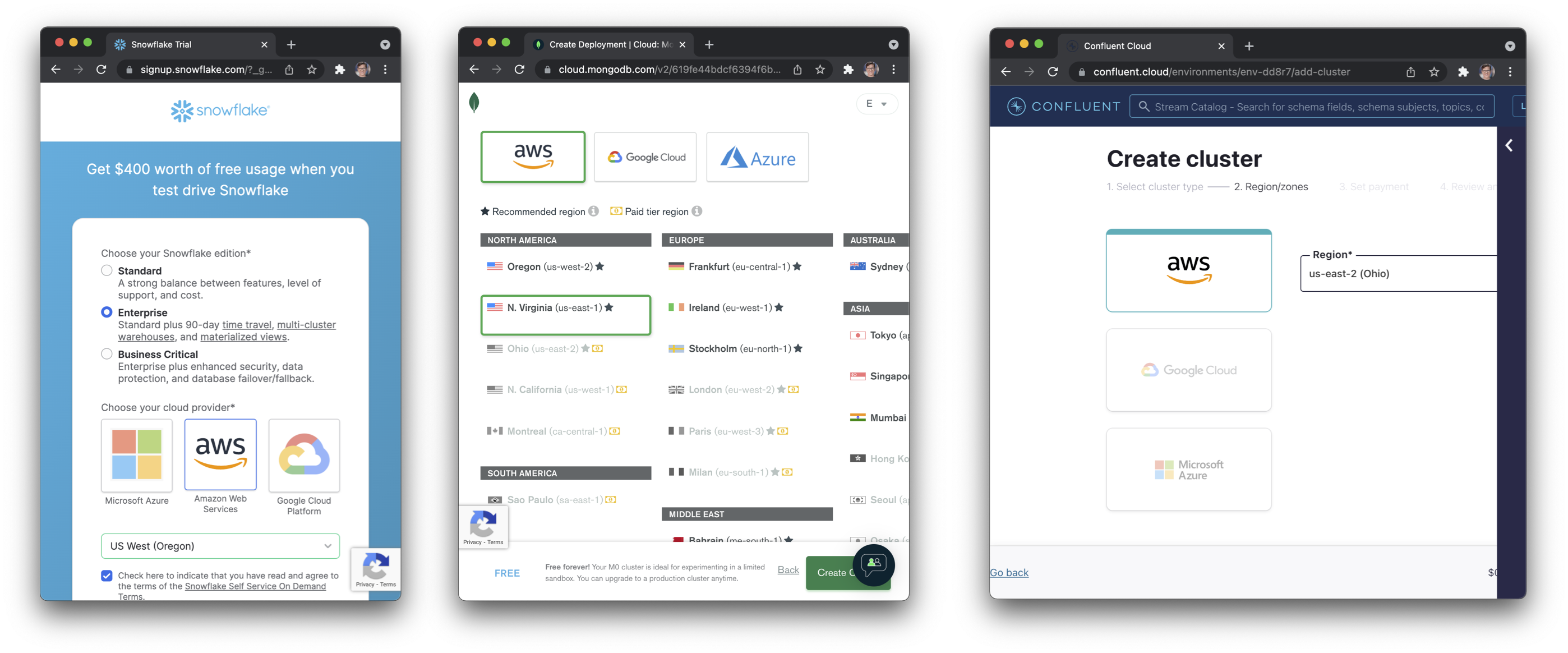
The screenshots above show the onboarding for Snowflake, Confluent, and MongoDB (Atlas). They all ask:
- What’s your cloud vendor?
- What region?
Note that the only options for the first questions are AWS, GCP, and Azure.
The other side of the equation of a potential cloud migration is—how much money you can save? And I think the truth it’s never going to be substantial, since no one wants to start a price war. Being in a fairly stable oligopoly seems pretty nice and cozy, and if I was cloud vendor, I wouldn’t try rock the boat.
The cloud in 2030
We’re roughly 10 years into the shift to the cloud, and even though it feels like it’s transformed how we build software, I think we’re still just getting started. I really wouldn’t be surprised to wake up in a world where most developers don’t interact with cloud vendors.
Big transformations tend to happen in two stages. The first step happens when some new technology arrives and people adopt to it in the simplest way that lets them retain their conceptual models from the existing world. The real transformations happens later, when you rethink the consumption model because the new world opens up new ways to create value. The way we consumed music didn’t change materially when Apple started selling songs online. The real transformation happened when providers like Spotify realized the whole notion of ownership didn’t matter anymore.
If you think about it from that angle, the last 10-15 years look a bit like a dumb “lift and shift”. Crudely speaking, we took computers and we put them in the cloud. Is that really the right abstraction for where we are? I don’t think so. I think new higher level tools will let us focus on building application code and not worry about the underlying infrastructure.
Startups are coming for your code
The forces I’ve talked about have been most clear when you look at Snowflake vs Redshift, but you can see it in other places too. Transactional databases is another very exciting area. But where I think we’ll see the most change is how software vendors will increasingly run customer code.
This isn’t exactly a new idea—Heroku launched in 2007, and AWS Lambda in 2014. Kubernetes has been this interesting trend in the last few years on what I think is still essentially an inevitable march towards a fully “serverless” world, whatever that means to you.
I wonder if a weird corollary of this is… maybe it’s actually really good for the planet? The computers sitting in the cloud are ridiculously underutilized—my guesstimate of average CPU utilization is that it’s maybe 10%? If I had a Ph. D. in bin packing, I’d go looking for a job at some serverless infrastructure provider right now.
One way to tell the story in 2030 looking backwards is that the cloud vendors needed software running on top of it, so they had to provide that themselves first, in order to drive cloud adoption. Luckily they already had a bunch of internal stuff they could ship! But eventually the market matured, and they could focus on the place in the stack where they had the strongest advantage.
Predictions
- The cloud market will grow to $1T/year in revenue. Ok, that’s almost entirely noncontroversial.
- Most engineers will never interact directly with cloud vendors, but through services on top of those.
- The database market (OLAP, OLTP, you name it) will be dominated by vendors running on top of cloud vendors, where the underlying layer is completely abstract.
- We will have some amazing new runtimes, finally figuring out the developer experience problems that are currently holding serverless solutions back.
- We will see a lot of partnerships between startups and cloud vendors, where a cloud vendor may concede an area and try to be a preferred partner with a startup instead.
- Kubernetes will be some weird thing people loved for five years, just like Hadoop was 2009-2013, but the world will move on.
- Resource utilization in the cloud will be much better, and engineers will spend an order of magnitude less time thinking about resource allocation and provisioning.
- IBM has finally given up on “hybrid multi-cloud”.
- YAML will be something old jaded developers bring up after a few drinks. You know it’s time to wrap up at the party at that point.
This generated a bunch of comments on Hacker News, most of which strongly disagree! Looking forward to see what the world looks like in 10 years.
Thanks to Josh Wills, Akshat Bubna, and Sarah Catanzaro for feedback on an earlier version of this post!
-
I’m ignoring the CDN world a bit here. It’s very clear right now that Cloudflare is doing an amazing job owning the stack all the way from developer experience to networking equipment. But frankly I don’t see any long-term foundational difference operating 300 small data centers vs 30 large ones. Cloudflare has done exceptionally well staying ahead of the innovation game, but I suspect the same economic forces that apply to AWS et al eventually apply to them too. ↩︎
-
A fun thing is I randomly had lunch with the Snowflake founders in 2012 and they offered me a job the next day. The company was like… 10 people in total? ↩︎
-
There was one major architectural difference of Snowflake vs Redshift. A very underappreciated tech shift is how much faster networks got around that time. Up until that point, the wisdom was “move compute to data”, but Snowflake bet early on a full decoupling. AWS launched Athena in 2016 which was based on Presto, not Redshift, and launched Redshift Spectrum in 2017 which lets you query data in S3 through Redshift. As a bizarre coincidence, Redshift just launched a serverless product today, which is something they probably should have done a long time ago. ↩︎
-
This is from DB rankings. ↩︎
-
A pretty long history about Redshift vs Snowflake, which also points out that AWS unintentionally ended up incentivizing their sales teams to recommend Snowflake to customers. ↩︎
-
The margins on EC2 is reportedly about 50% and about 60% for AWS as a whole. Just comparing instance pricing for Redshift and for EC2 for equivalent instance types also gives a good idea of the Redshift markup above EC2. ↩︎
-
Snowflake is a public company and you can compute their margins from their latest quarterly report. ↩︎
-
Security is another topic that drives this, although security to some extent works against startups: the bar to adopt additional AWS products is often lower than completely new vendors. ↩︎
-
Cloudflare is actively going after the very high AWS egress fees and it’s going to be interesting to see how that plays out. ↩︎