Approximate nearest news
As you may know, one of my (very geeky) interests is Approximate nearest neigbor methods, and I’m the author of a Python package called Annoy.
I’ve also built a benchmark suite called ann-benchmarks to compare different packages. Annoy was the world’s fastest package for a few months, but two things happened.
- FALCONN (FAst Lookups of Cosine and Other Nearest Neighbors) is a new library based on Locality Sensitive Hashing
- NMSLIB authors came up with an impressive set of improvements to their algorithms.
The quest for the fastest nearest neighbor algorithm intensifies. (Except, I expect Google has already found a method that’s 10x faster and works at a 1,000,000x larger scale).
What makes me excited is that ann-benchmarks has become the standard benchmark for approximate nearest neighbor algorithms. I’m glad, because open objective benchmarks drives progress. Both FALCONN and NMSLIB have been using ann-benchmarks for their tests and the authors contributed code back to ann-benchmarks to support their libraries.
The situation looks like this right now:
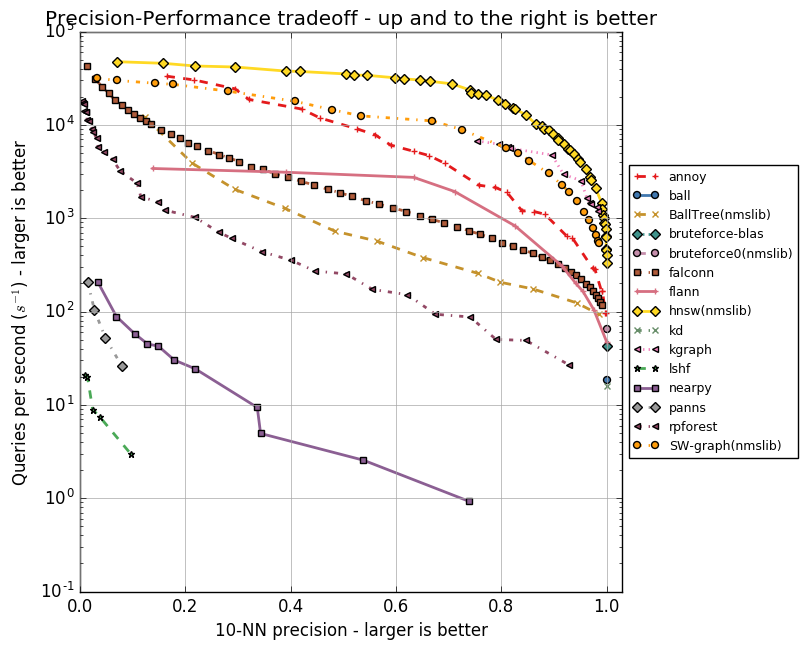
If you look at the higher precision results (0.8 and up), Annoy is now the fourth fastest library. FALCONN and NMSLIB (both SW-graph and hnsw) are better. In fact, hnsw is faster by almost an order of magnitude, which is very impressive. This is a new algorithm that was recently published in a paper: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs (the paper also features a benchmark against Annoy).
Using Annoy to visualize large datasets
A cool thing to do when you have a high dimensional data set is to embed it in 2D or 3D for visualization. There are algorithms that preserve similarity during the embedding, the most widely used one being t-SNE.
A great paper came out that improves on t-SNE for 2D and 3D embedding of large high dimensional data sets: Visualizing Large-scale and High-dimensional Data. The authors of the paper propose a new method that they implement using Annoy – it also mentions ann-benchmarks. Unfortunately I haven’t seen any code yet (I’ve been tempted to build something) but there’s an R implementation that doesn’t use Annoy.
For any readers of this blog who is (a) interested in approximate nearest neighbors (b) based in Philadelphia (I expect the intersection of those sets to be $$ \approx \emptyset $$): I’m going to talk about Annoy at the DataPhilly meetup on June 15. It’s going to be quite similar to my talk at the NYC Machine Learning meetup.
Tagged with: approximate nearest neighbors, math