Are data sets the new server rooms?
This blog post Data sets are the new server rooms makes the point that a bunch of companies raise a ton of money to go get really proprietary awesome data as a competitive moat. Because once you have the data, you can build a better product, and no one can copy it (at least not very cheaply). Ideally you hit a virtuous cycle as well, where usage of your system once it takes of gives even more data, which makes the system even better, which attracts more users…
The behavior of machine learning models with increasing amounts of data is interesting. If you’re building a machine learning based company, first of all you want to make sure that more data gives you better algorithms.
But that’s a necessary, not sufficient condition. You also need to find a sweet spot where
- It’s not too easy to collect enough data, because then the value of your data is small
- It’s not too hard to collect enough data, because then you’re going to spend way too much money to solve the problem (if ever)
- The value of the data keeps growing the more data you get
In the recommender system world (where I spent 5 years) it’s not uncommon for algorithms to basically converge after say 100M or 1B data points. It depends on how many items you have, of course. Some class of models converge before they are even useful, in which case obviously there’s no value in more data. Xavier Amatriain has an excellent Quora answer that I urge you to check out if you want to learn more.
Anyway let’s simplify the problem. Let’s consider the behavior of some algos:
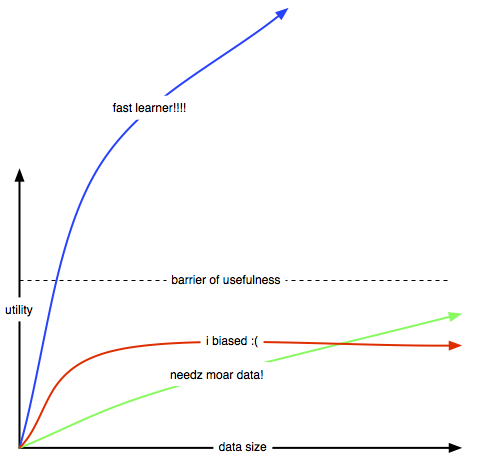
- The blue model represents problems where it’s really easy to get good data pretty cheaply. For instance, a cat vs dog classifier is not a useful piece of tech because the value of getting that training data is roughly $0. I would worry about this for any company building a general purpose image classifier, for instance. Or if you’re building a recommender system with 10k items it might be good enough with 10M ratings already. Having 100B ratings isn’t necessarily more valuable.
- The red model can happen in cases where your data comes from a different distribution or your loss function isn’t close to what the product requires. In those cases more data is useless at some point. If you’re building a movie recommender system by scraping web text it might just converge to a decent but not good enough model. (Here’s another hypothesis: maybe collecting passive data from driving a car isn’t enough to learn how to actively drive a car?)
- The green model is when your problem may require such a ridiculous amount of data that it’s not practical. For instance building a general purpose question and answer service that can solve all the questions in the world isn’t that hard from a ML perspective if you have an infinite amount of data of questions and answers. But it’s probably going to be useless with less than terabytes or petabytes of input data. If I tried to build a virtual assistant, this would be my biggest concern.
Here are some sweet spots where I think you can build up a data set, but it’s hard. Hard is good because it means once you did it, you have a moat:
- Detect fraud in transaction data
- Predict which loans are going to default
- Detect crimes from security footage
Hard to remember? Here’s a handy table I made
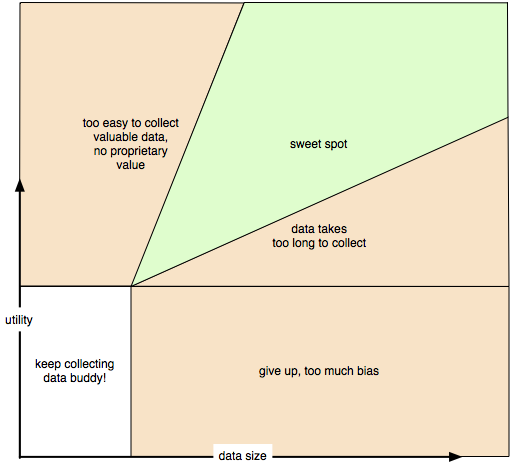
I think the general idea is pretty valid. But is it 100% correct? Probably not. Is it oversimplified? Oh yeah, to the extreme.
Tagged with: data, machine learning