Data architecture vs backend architecture

A modern tech stack typically involves at least a frontend and backend but relatively quickly also grows to include a data platform. This typically grows out of the need for ad-hoc analysis and reporting but possibly evolves into a whole oil refinery of cronjobs, dashboards, bulk data copying, and much more. What generally pushes things into the data platform is (generally) that a number of things are
- Not latency critical so can run much later, maybe up to 24h (as opposed to reactive synchronous jobs sitting on a request-response cycle)
- Easier to express as batch job operating on a large dataset rather than operating on each request
Reporting is a decent example. Let’s say you need to import all transactions into your accounting system. Rather than doing it directly from the backend, it might be a lot easier to just write a script to do it every 24h.
Training machine learning models is another example. Let’s say you are building a fraud detection system and you have a machine learning model to detect if some user action is fradulent. Training the model might take an hour but predictions are quick. It’s much easier to re-train the model say every 24h or even every week or month. You can then serialize the model and use that for predictions in your backend system.
At Spotify the data platform started with royalty reporting, but quickly rebuilt the toplists to be a nightly data job. The data platform kept growing, in particular the music recommendation system, which became a humongous data pipeline. We retrained the core models every few weeks but typically regenerated personalized recommendations every night. That was frequent enough that people wouldn’t run out of recommendations.
Why bother?
Why bother with a data platform? Because things typically get 10x easier to build and ship. Pushing work out of the backend into a separate data platform helps with a few things:
- You don’t have to worry about latency.
- You can control the flow yourself (rather than being at the mercy of a user request waiting for a response)
- You can generally write things in a much more fault tolerant way (batch processing is often easier to write as a set of idempotent operations)
- Batch processing can be a lot more efficient (generating music recommendations for 1,000,000 users is maybe only 1,000 times more work than generating for 1 user)
- If things fail, it’s not the end of the world, since you often fix the bug within the next day or so and just re-run the job
For instance, consider the basic feature of building a global toplist that updates itself in real time, say showing the top news articles on a news website. I’m willing to bet a substantial amount of money that it’s orders of magnitude harder to do this purely in the backend compared to building a cron job in the data platform that updates it every hour or every day and pushes the result back into the backend.
So you do you do it (in the least hacky way)?
Of course, backend architecture is a bit more mature, and there’s about 1,000 blog posts about best practices. Martin Fowler is one that comes to mind for instance. When we’re building backend systems, we’ve been taught things like:
- Avoid integration databases (each system should have its own database, and two systems can never touch the same database)
- Database queries should be simple (typically refer to an exact key and joining as few tables as possible, ideally zero)
- Use transactions (and constraints/keys/etc) for data integrity
- Lots of unit tests
- Lots of integration tests
- Decompose larger services (aka “monoliths”) into smaller ones (aka “microservices”)
… aaaaanyway, you can throw all/most of this out the window when you go to the data platform!

Oil painting featuring the defenestration of Prague (1618)
The data side: the wild west
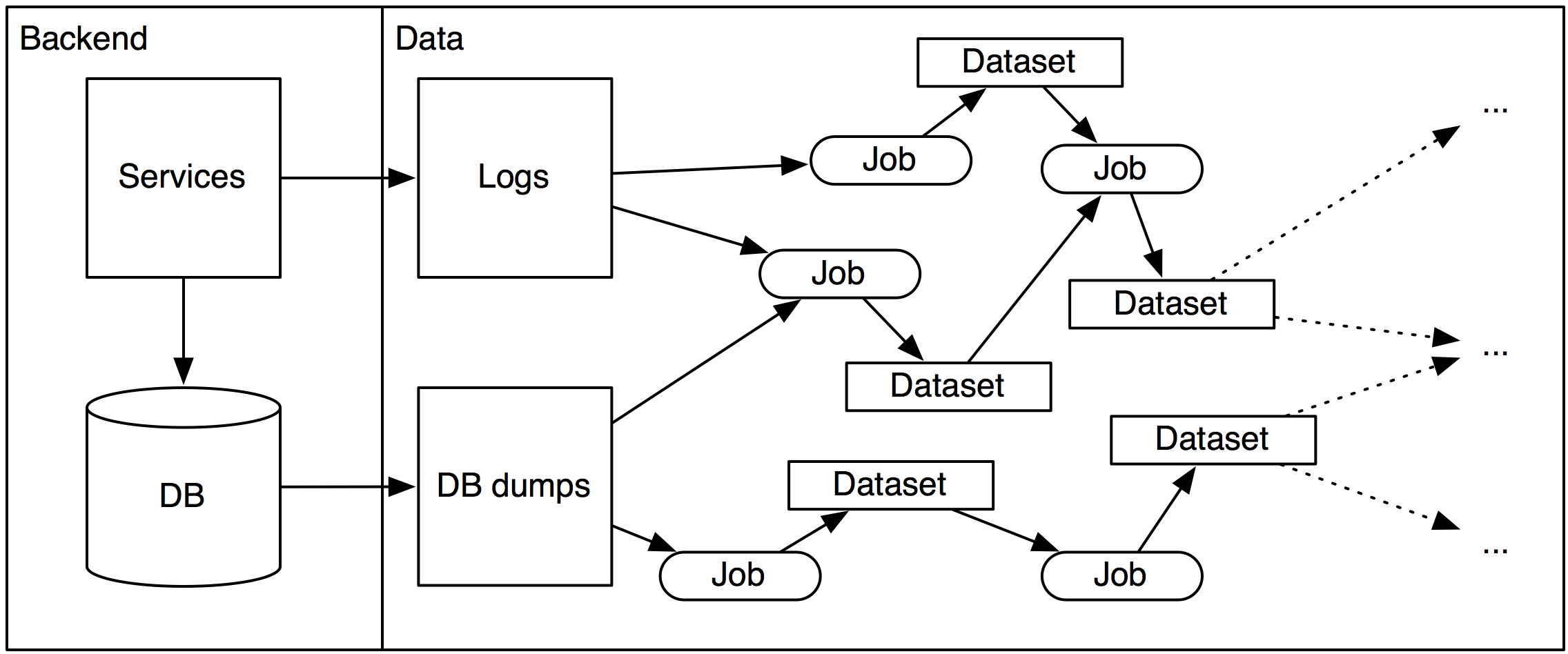
What I’ve seen in terms of infrastructure is typically one of these things as a starting point:
- Backend logs are shipped to some data store
- Backend production databases are dumped to some data store
Back in the days, this data store was typically Hadoop (HDFS) although these days it’s often some scalable database such as Redshift. There’s lots of different solutions and I’m not here to opine on any of them.
Notes on data latency
Anything in the data platform is typically delayed (at Spotify typically up to 24h or even more). If it’s not delayed, then it should be considered delayed, meaning anything operating on the data should not be latency critical.
Can you have a data platform that operates on real-time database data rather than a delayed database dump? Yes, in theory. But I think it can encourage really bad practices. For instance if you have cron jobs operating on the production database, then it’s easy to do things like writing data back to the database which now creates an integration database with multiple writers and consumers of the same table. This can be a mess! For this reason, the right separation should be that (a) cron jobs operate on delayed data (b) any communication back to the backend system happens through internal endpoints.
And another word of caution: don’t give business people access to real-time data! They will start to demand it for everything and you will have to support it forever.
Anyway, what happens on the data side? In my experience, and in my opinion, anything goes. Let’s talk about some of those things:
Integration databases
For instance, the traditional constraint that services should not touch each other’s databases and that those layers should be respected. This avoids the so called “integration database” antipattern where you have multiple writers and readers of the same data. In the data world, that rule goes out the window. On the data side, I find it completely kosher to join across 3 different dataset from different services. Why is this acceptable? I think it boils down to two things
- Schema changes that break any downstream consumers are not the end of the world. You are going to have to update some queries, that’s it.
- If things break, then you can typically fix it and re-run the job. If some report isn’t generated at midnight UTC, you can fix the job in the next few hours and few will complain.
- All queries are read-only. That means you never have to worry about transaction integrity, or reading inconsistent data.
My conclusions is that integration databases are terrible for backend systems but great and fun in the data layer.
Mega queries
A backend system will have to deal with low-latency low-throughput queries, that usually touch only one user at a time. But that user is making a request and waiting for a response, so queries need to be fast. So how do you make queries fast?
- Avoid as many joins as possible. When needed, stick to very simple, indexed joins (typically left join from table A to B)
- Every query should refer do a particular item id, eg.
... where user_id = 234or similar.
I get incredibly suspicious any time I see any queries in a backend system that are more complex than a couple of tables and one or two where conditions.
In the data world, those things don’t matter at all. Almost all queries are going to cut “across” all/most of the data, and in fact most queries will boil down to “full table scans”. Queries spanning pages looking like they were written by a early 20th century German philosopher? Bring it on!
This is basically the difference between OLTP and OLAP which are different types of query pattern. There’s probably lots of literature if you’re willing to go deep!
Testing
I’m writing this somewhat apologetically, maybe with a sense of guilt as I’m admitting some dark secret. I’m a big proponent of very thorough testing, but getting any reasonable amount of test coverage on the data side is… hard.
For a backend system, you’re sort of implementing functions like $$ y = f(x) $$ where $$ x $$ is an input (say a response from a 3rd party API) and $$ y $$ is the result (say, the API response transformed to an internal representation). That’s really easy to test! Sometimes you have functions like $$ S_{n+1} = f(S_n, A) $$ where $$ S_{i} $$ is the “state” and $$ A $$ is some action. But the state and the action is super tiny and can be reasonably well represented inside a unit test.
On the data side, the $$ x $$ and $$ S_i $$ are huge. This means any unit test basically ends up being 99% just setting up all the input data. But because the input data is super high dimensional, it also means modeling edge cases becomes exponentially harder. The just to throw a wrench into this, data pipelines can often be nondeterministic (machine learning models) or have very subjective outputs to the point where you can’t just write up a bunch of assertions easily. For all these reasons, I’ve found that tests for data pipelines have pretty low fidelity (they catch few bugs) and have high maintenance costs. Sad! I like to have a few basic tests to make sure things run, but verifying correctness might not always be worth it.
Conclusion
I’ve found it useful to push as much as you can out of the backend into the data platform. This includes lots of things like
- Sending (non-transactional) emails to users (like personalized marketing emails)
- Generating search indexes
- Generating recommendations
- Reporting
- Generating data for business people
- Training machine learning models
All of those things could be built into the backend system, but should probably be run as cronjobs in a data platform instead. This will reduce the complexity of your code by (roughly) an order of magnitude.
Side note
I just wanted to mention it’s been three months since my last blog post. I’m sorry! My second daughter was born in November and life has been pretty busy (but fun!). It didn’t help that my last two posts both hit Hacker News front page, putting the bar really high. I have a bunch of low key posts in my head I’m planning to post in the next couple of months. Keep an eye out!
Tagged with: software, data, math