The half-life of code & the ship of Theseus

As a project evolves, does the new code just add on top of the old code? Or does it replace the old code slowly over time? In order to understand this, I built a little thing to analyze Git projects, with help from the formidable GitPython project. The idea is to go back in history historical and run a git blame (making this somewhat fast was a bit nontrivial, as it turns out, but I’ll spare you the details, which involve some opportunistic caching of files, pick historical points spread out in time, use git diff to invalidate changed files, etc).
In moment of clarity, I named “Git of Theseus” as a terrible pun on ship of Theseus. I’m a dad now, so I can make terrible puns. It refers to a philosophical paradox, where the pieces of a ship are replaced for hundreds of years. If all pieces are replaced, is it still the same ship?
The ship wherein Theseus and the youth of Athens returned from Crete had thirty oars, and was preserved by the Athenians down even to the time of Demetrius Phalereus, for they took away the old planks as they decayed, putting in new and stronger timber in their places, in so much that this ship became a standing example among the philosophers, for the logical question of things that grow; one side holding that the ship remained the same, and the other contending that it was not the same.
It turns out that code doesn’t exactly evolve the way I expected. There is a “ship of Theseus” effect, but there’s also a compounding effect where codebases keep growing over time (maybe I should call it “Second Avenue Subway” effect, after the construction project in NYC that’s been going on since 1919).
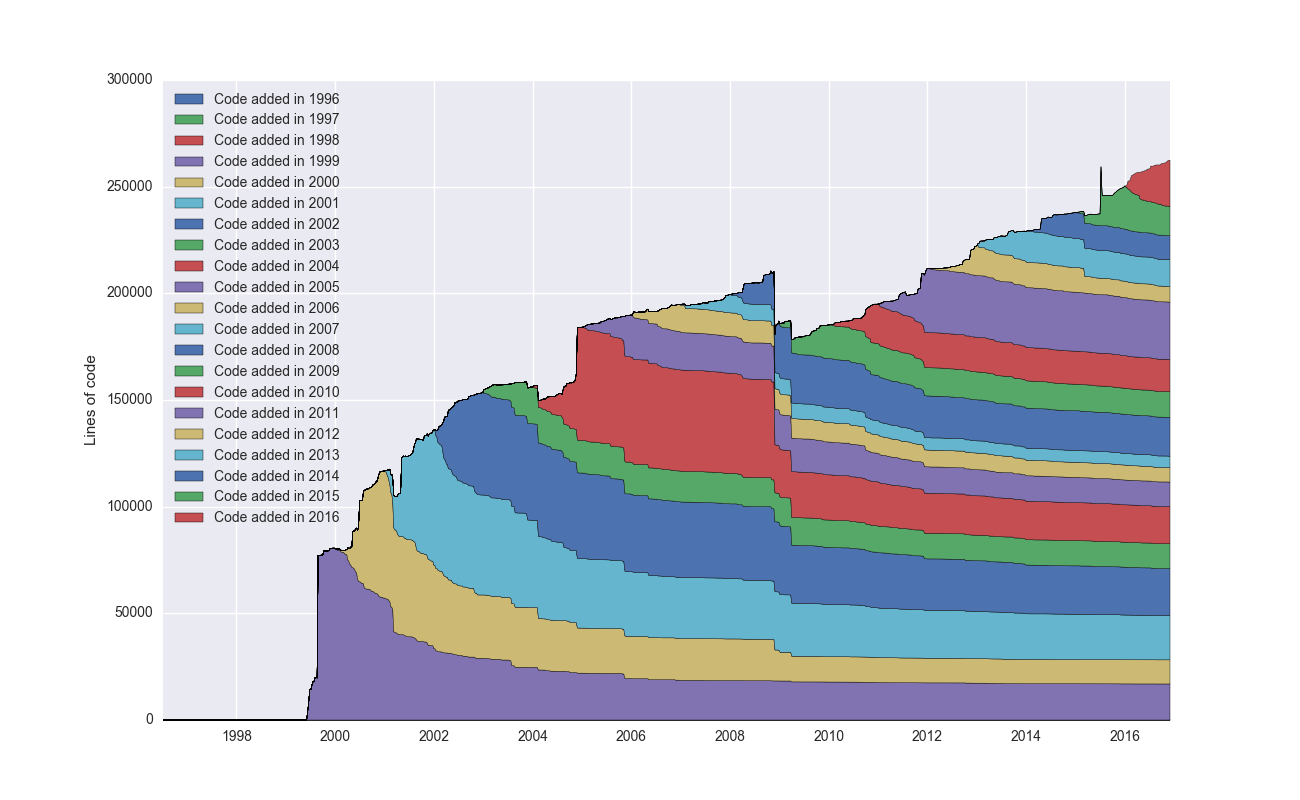
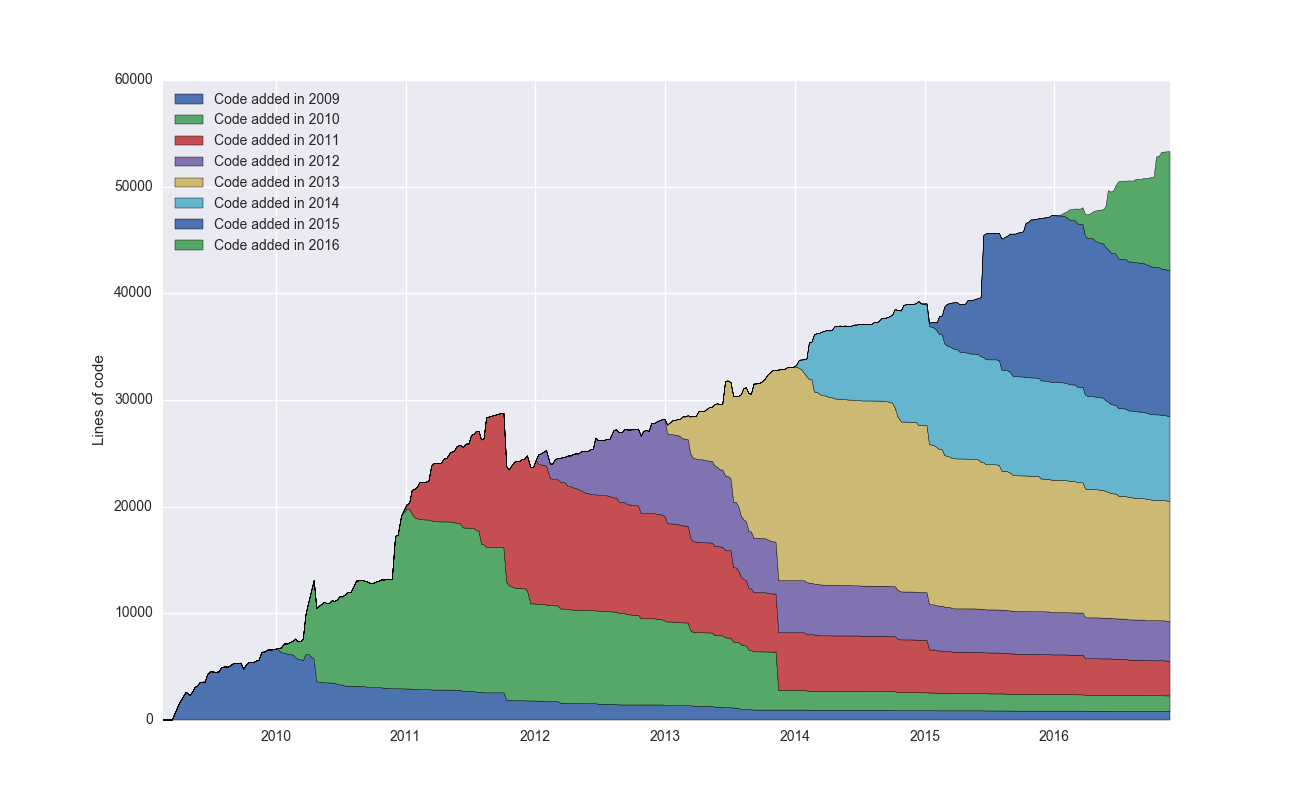
Let’s start by analyzing Git itself. Git became self-hosting early on, and it’s one of the most popular and oldest Git projects:
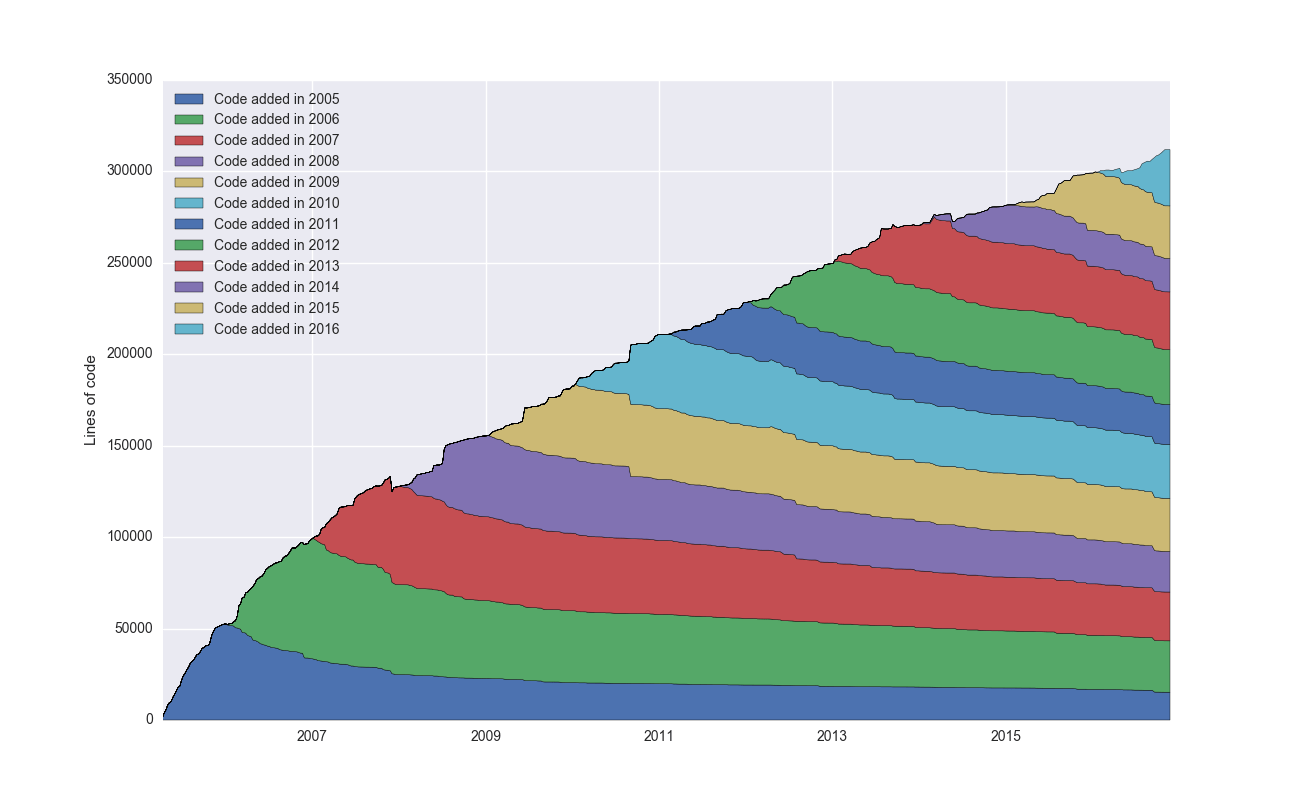
This plots the aggregate number of lines of code over time, broken down into cohorts by the year added. I would have expected more of a decay here, and I’m surprised to see that so much code written back in 2006 is still alive in the code base – interesting!
We can compute the decay for individual commits too. If we align all commits at x=0, we can look at the aggregate decay for code in a certain repo. This analysis is somewhat harder to implement than it sounds like because of various stuff (mostly because newer commits have had less time, so the right end of the curve represents an aggregate of fewer commits).
For Git, this plot looks like this:
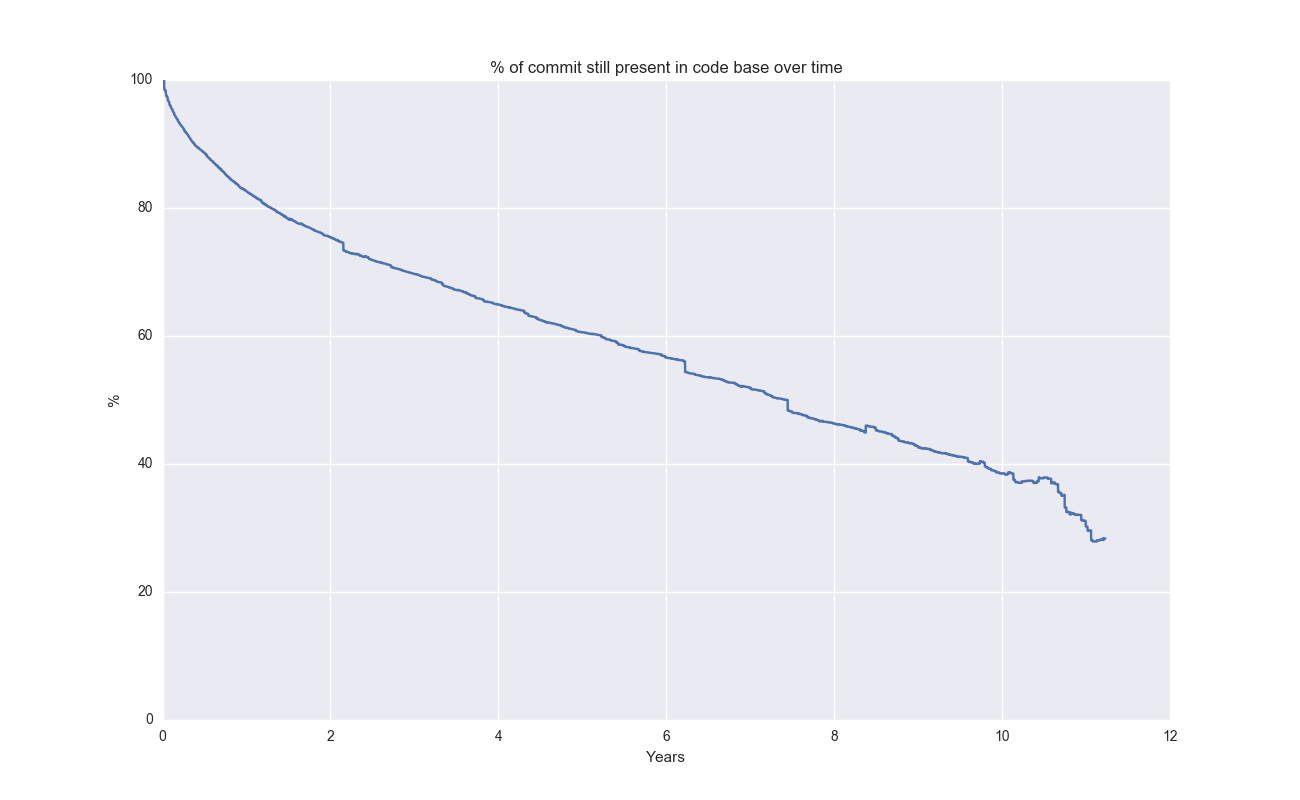
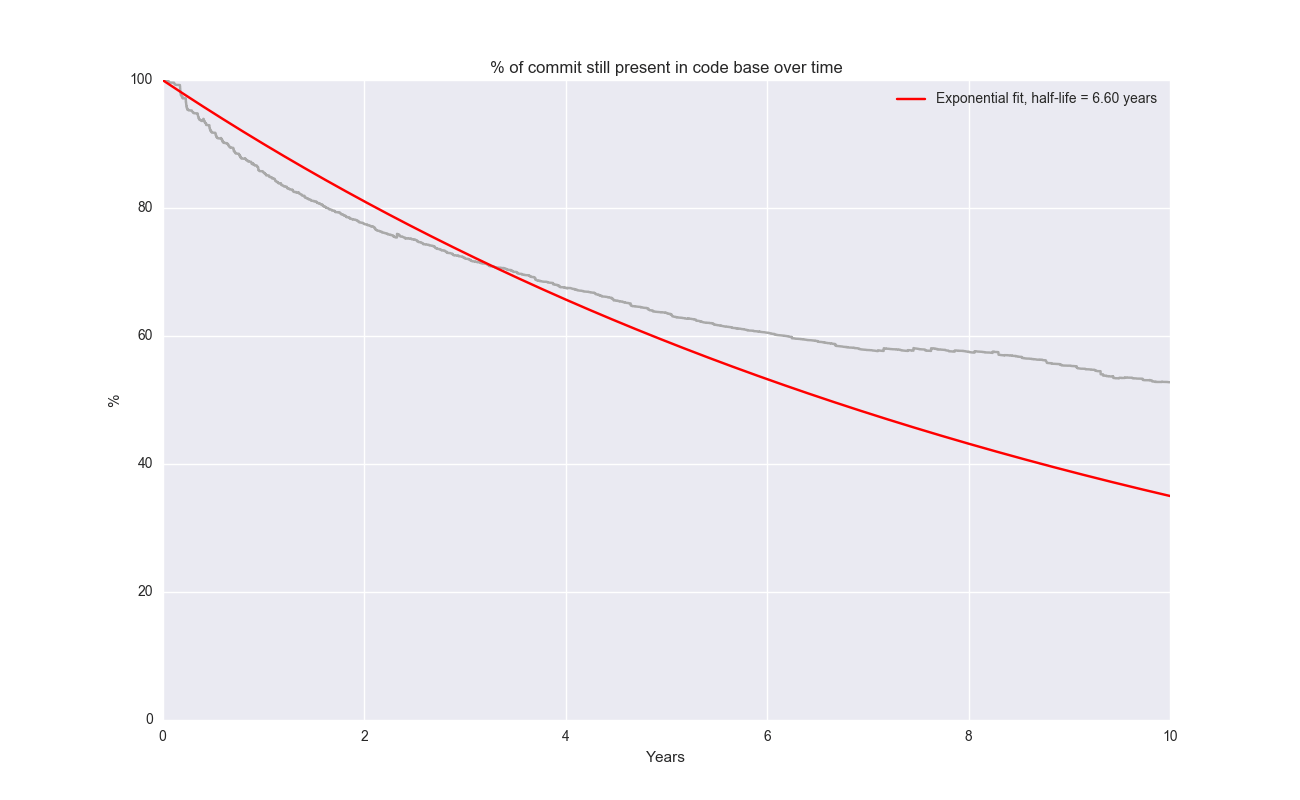
Even after 10 years, 40% of lines of code is still present! Let’s look at a broader range of (somewhat randomly selected) open source projects:
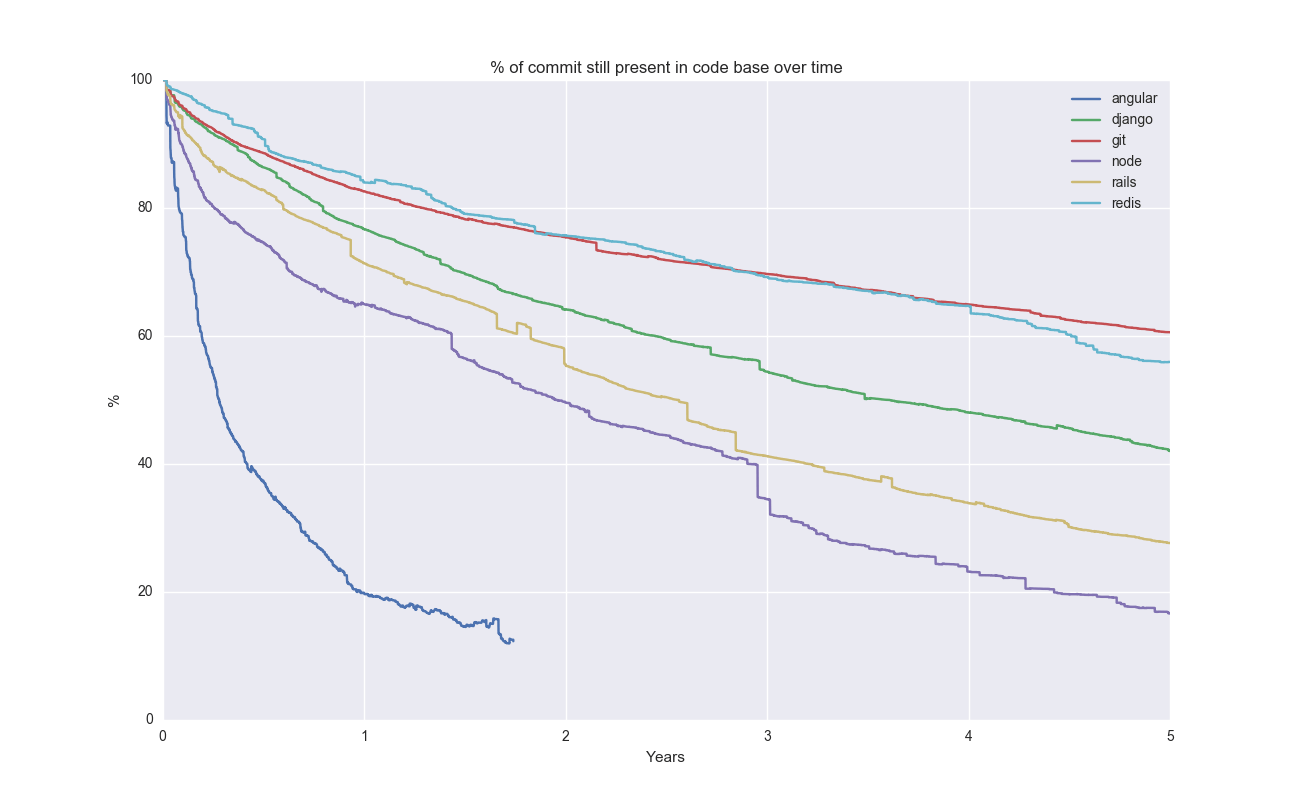
It looks like Git is somewhat of an outlier here. Fitting an exponential decay to Git and solving for the half-life gives approx ~6 years.
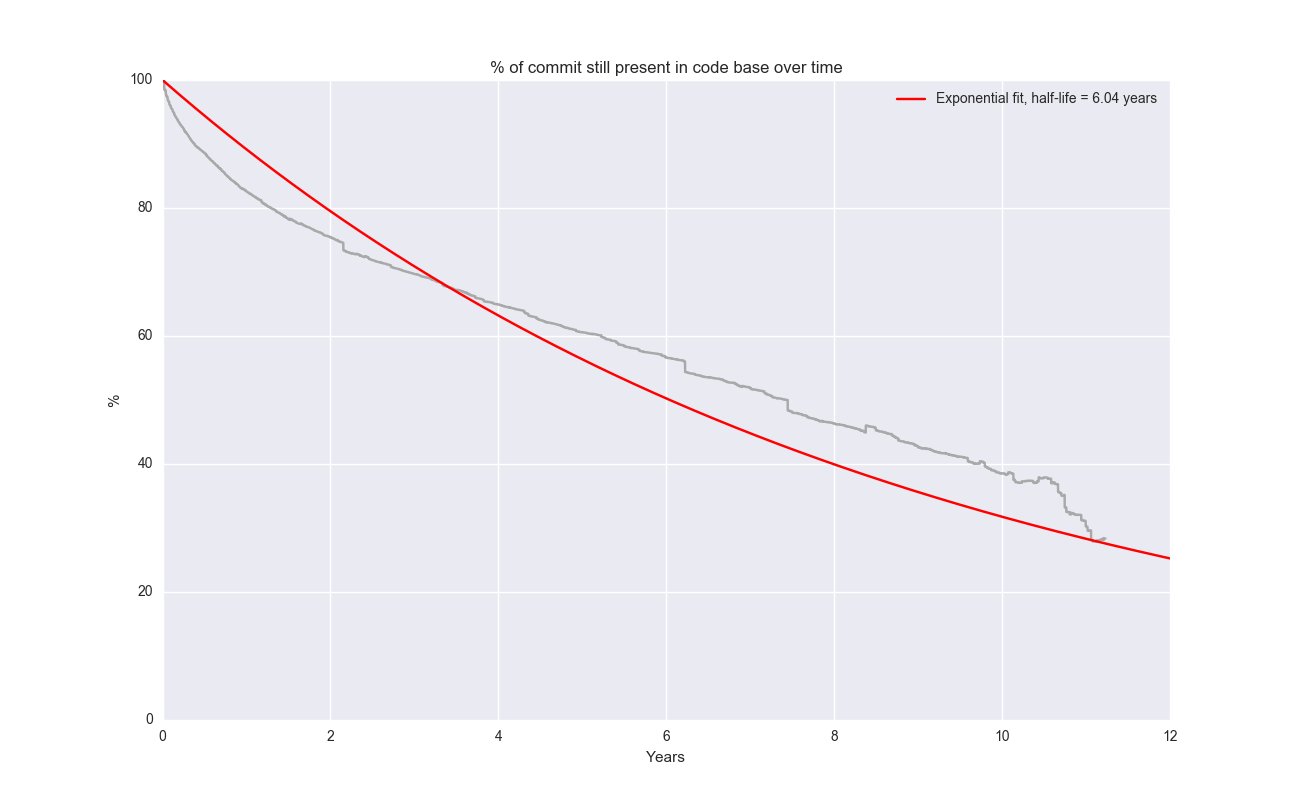
Hmm… not convinced this is necessarily a perfect fit, but as the famous quote goes: All models are wrong, some models are useful. I like the explanatory power of an exponential decay – code has an expected life time and a constant risk of being replaced.
I suspect a slightly better model would be to fit a sum of exponentials. This would work for a repo with some code that changes fast and some code that changes slowly. But before going down a rabbit hole of curve fitting, I reminded myself of von Neumann’s quote: With four parameters I can fit an elephant, and with five I can make him wiggle his trunk. There’s probably some way to make it work, but I’ll revisit some other time.
Let’s look at a lot of projects in aggregate (also sampled somewhat arbitrarily):
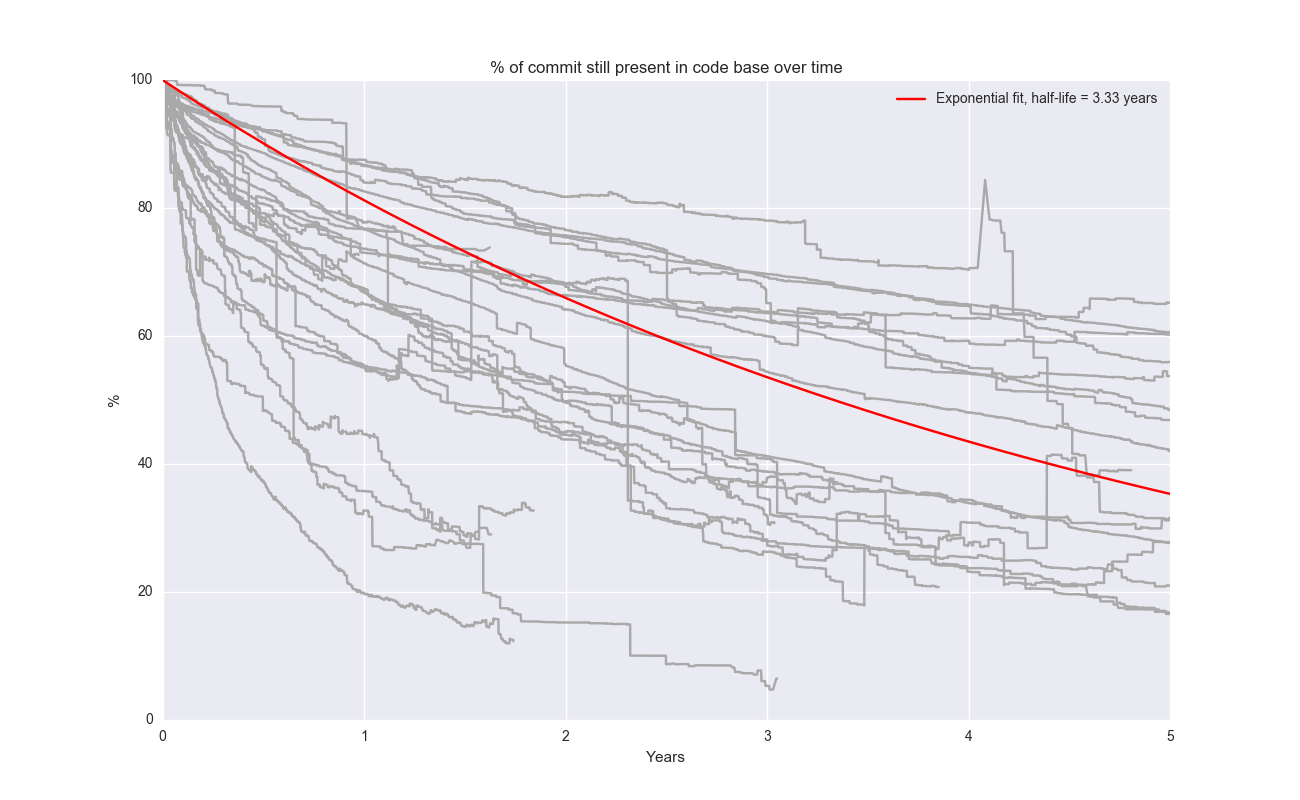
In aggregate, the half-life is roughly ~3.33 years. I like that, it’s an easy number to remember. But the spread is big between different projects. The aggregate model doesn’t necessarily have super strong predictive power – it’s hard to point to a arbitrary open source project and expect half of it to be gone 3.33 years later.
Moar repos
Apache (aka HTTPD) is another repo that goes way back:
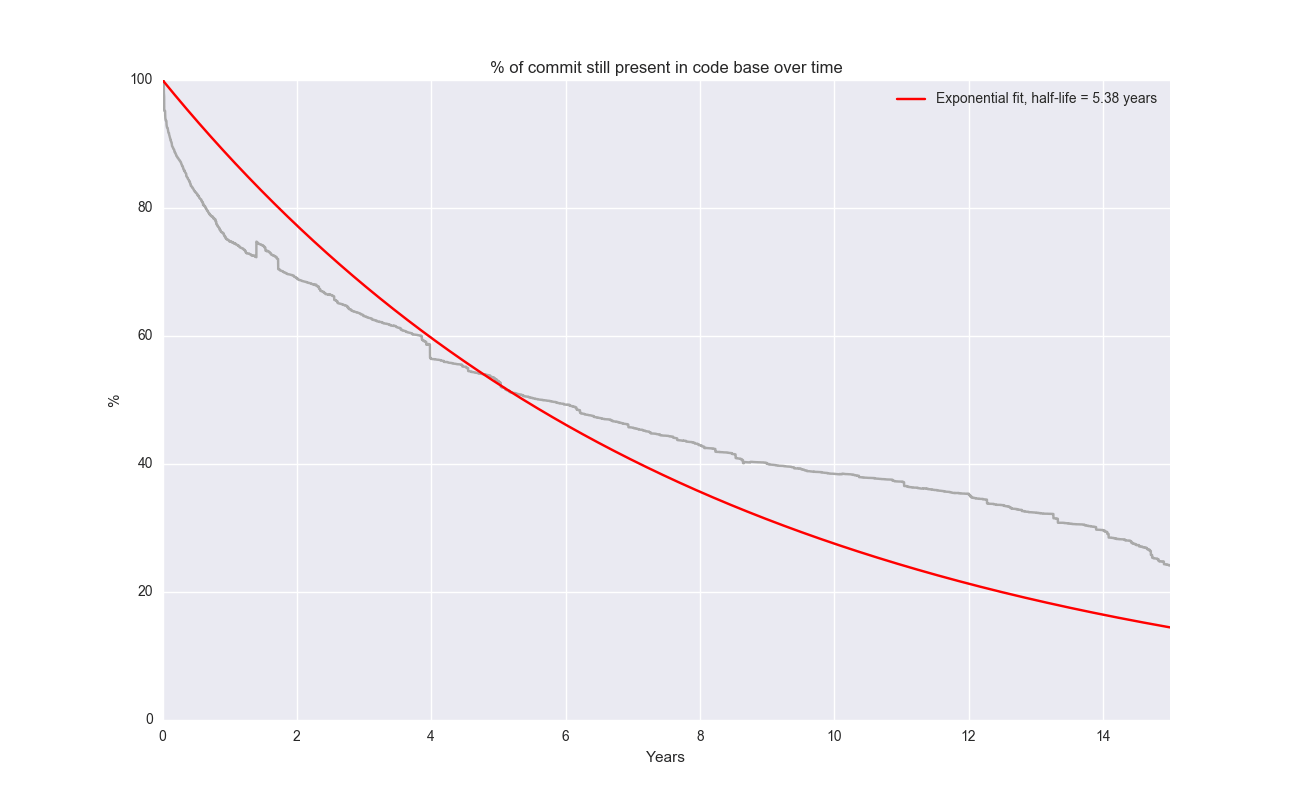
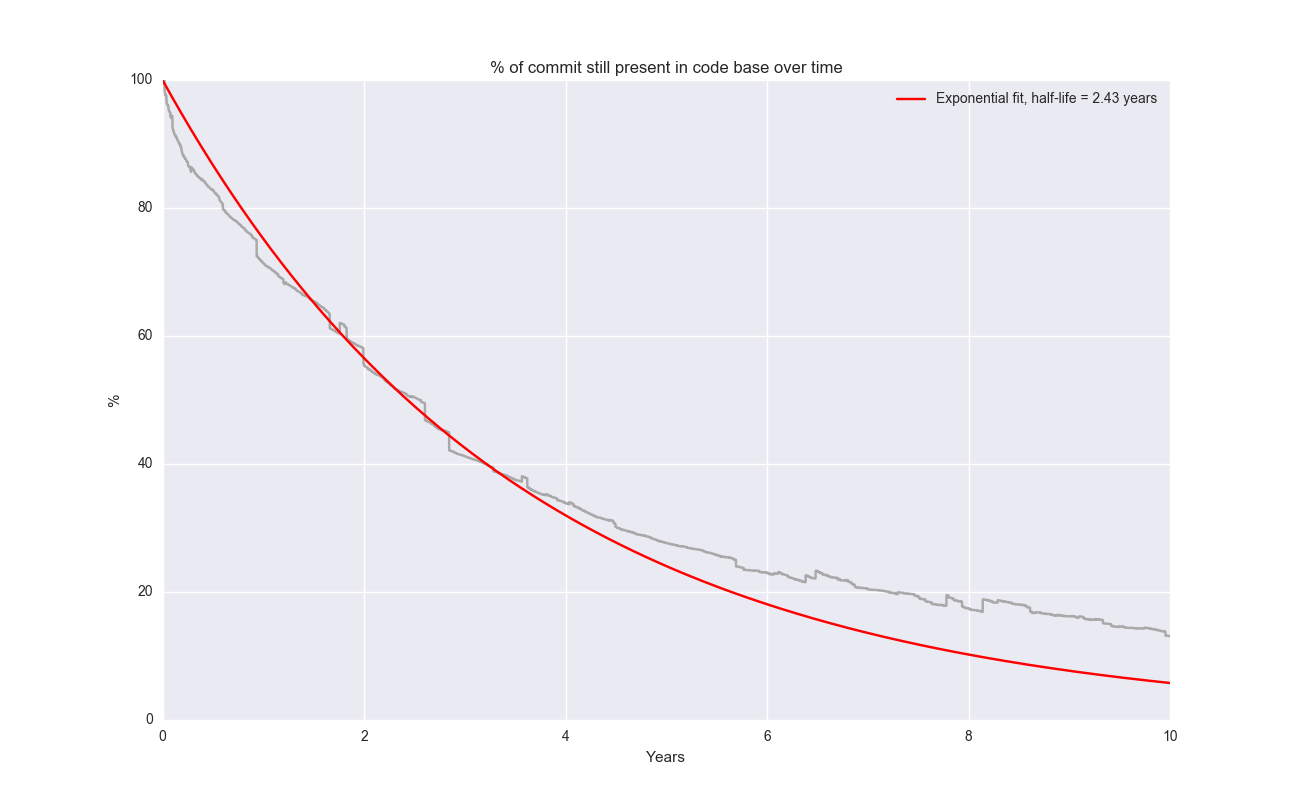
Beautiful exponential fit!
Wanna run it for your own repo? Again, code is available here.
The monster repo of them all
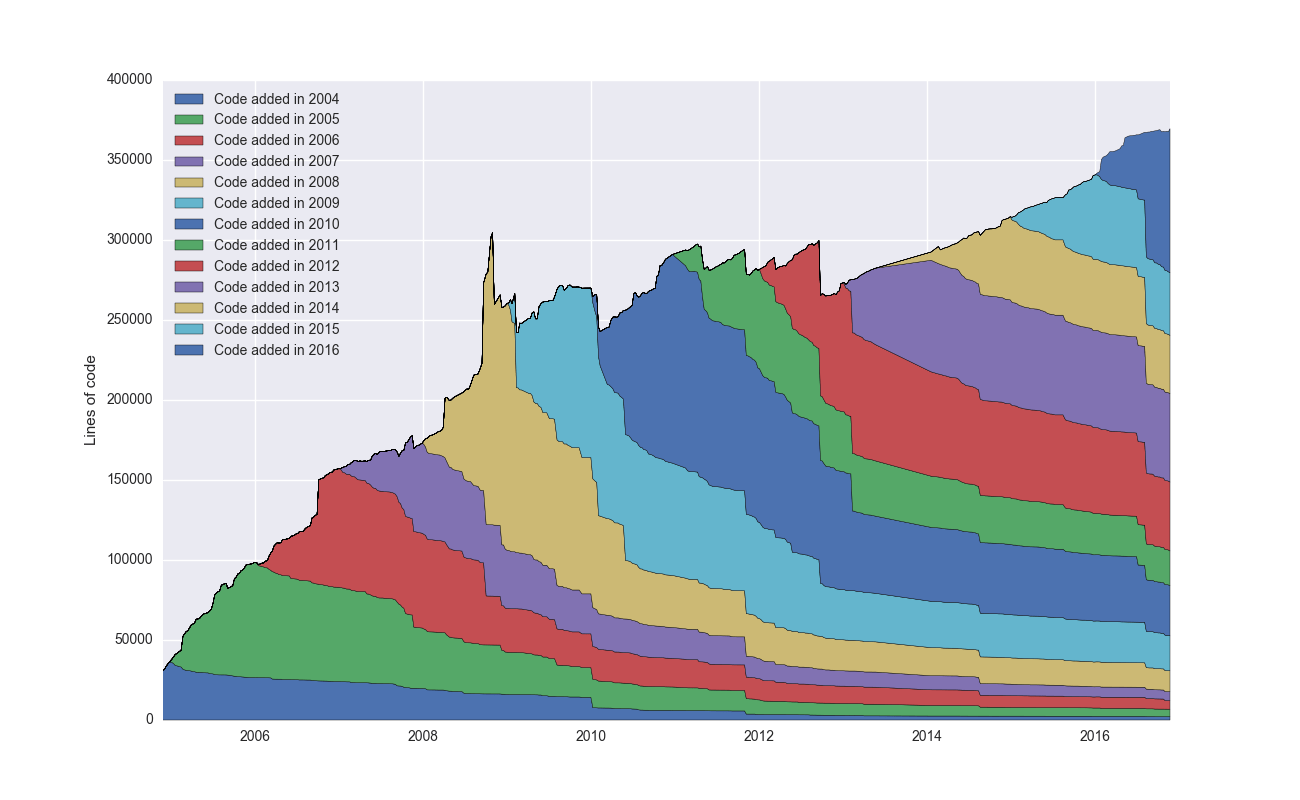
Note that most of these repos took at most a few minutes to analyze, using my script. As a final test I decided to run it over the Linux kernel which is HUGE – 635,229 commits as of today. This is 16 times larger than the second biggest repo I looked at (rails) and took multiple days to analyze on my shitty computer. To make it faster I ended up computing the full git blame only for commits spread out at least 3 weeks and also limited it to .c files:
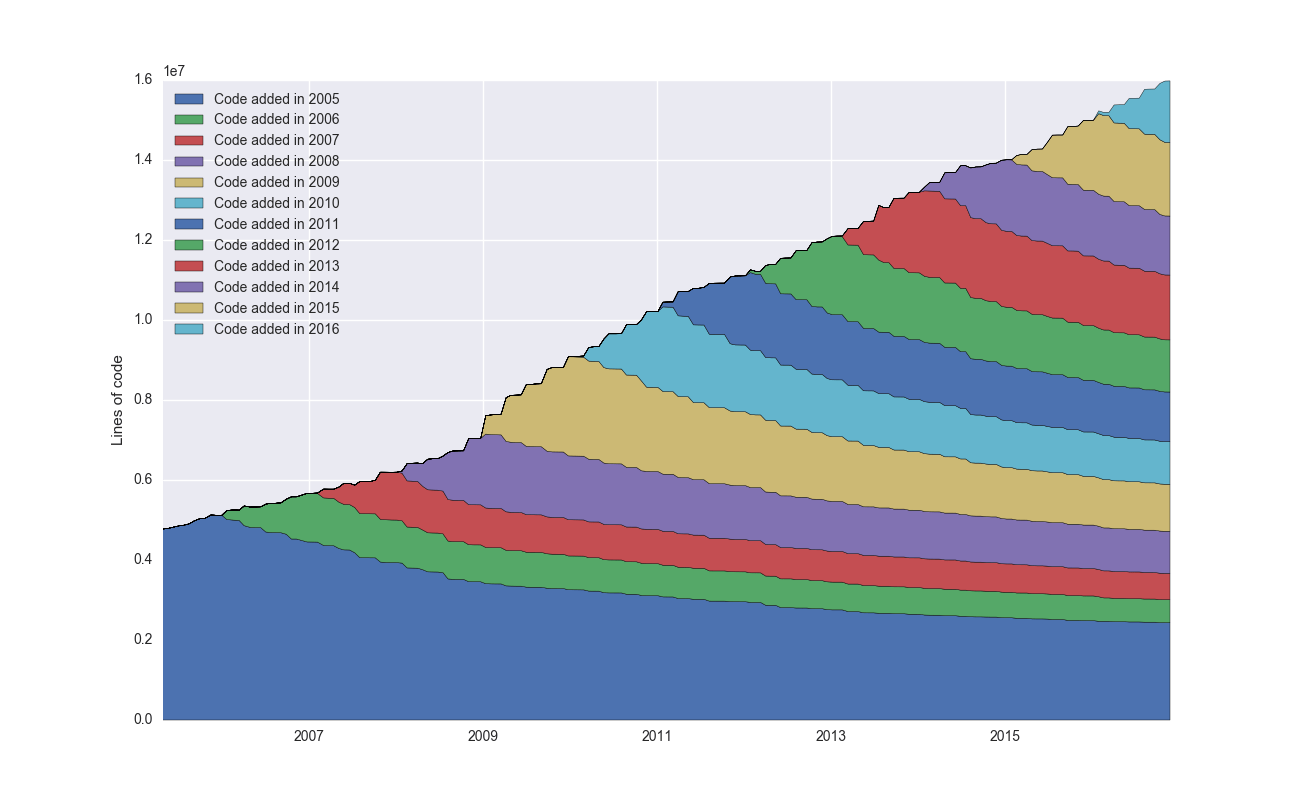
The squiggly lines are probably from the sampling mechanism. But look at this beauty – a whopping 16M lines! The code contribution from each year’s cohort is extremely smooth at this scale. Individual commits have absolutely no meaning at this scale – they cumulative sum of them is very predictible. It’s like going from Newton’s laws to thermodynamics.
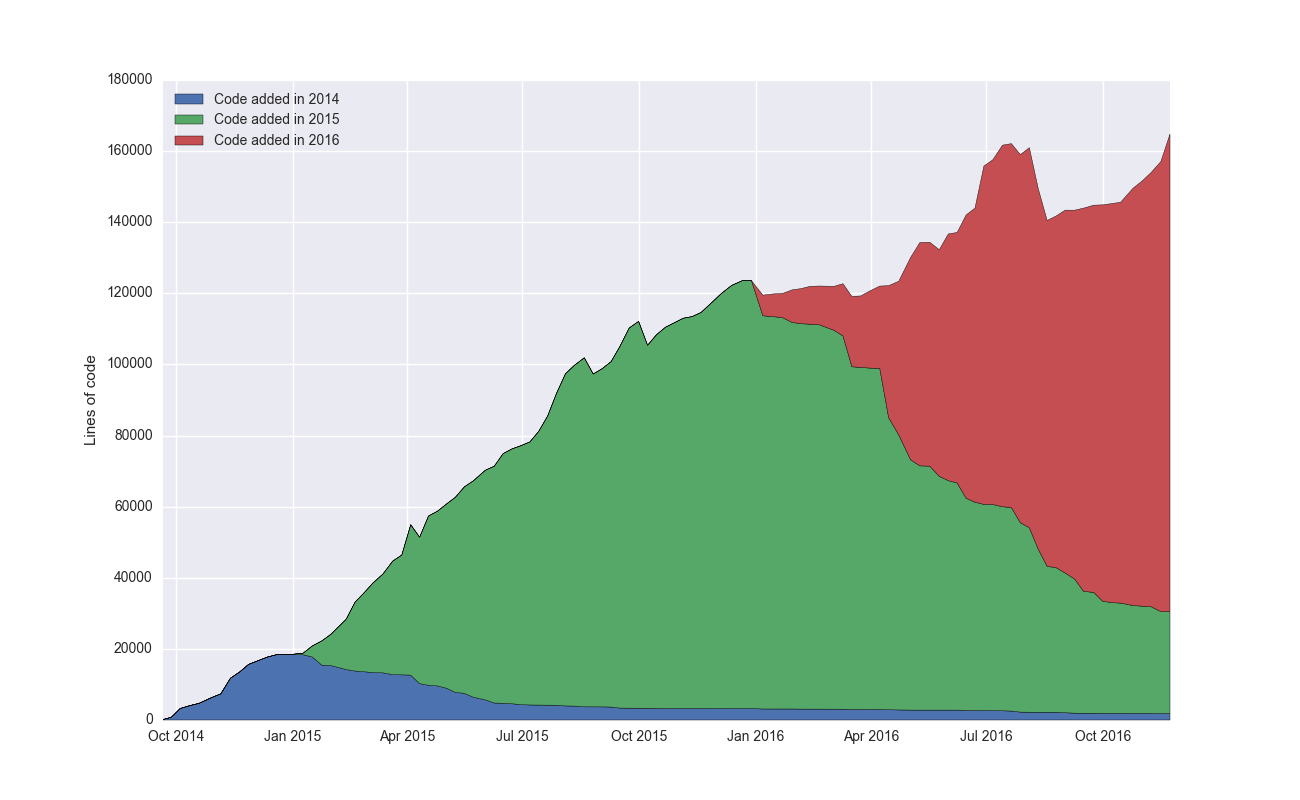
Linux also clearly exhibits more of a linear growth pattern. I’m speculating that this has to do with its high modularity. The drivers directory has by far the most number of files (22,091) followed by arch (17,967) which contains support for various architectures. This is exactly the kind of things you would expect to scale very well with complexity, since they have a well defined interface.
Somewhat off topic, but I like the notion of how well a projects scales with complexity. A linear scalability is the ultimate goal, where each one marginal feature takes roughly the same amount of code. Bad projects scale superlinearly, and every marginal feature takes more and more code.
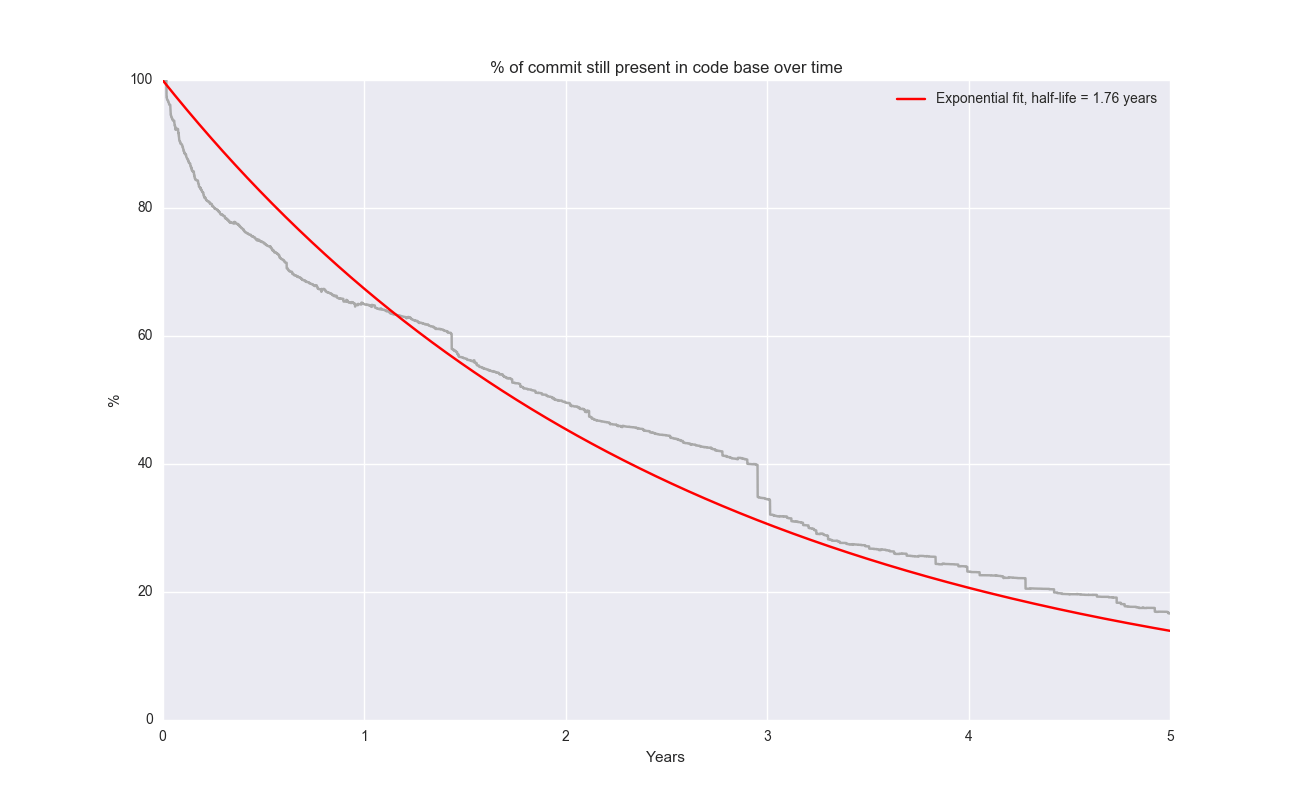
It’s interesting to go back and contrast Linux to something like Angular, which basically exhibits the opposite behavior:
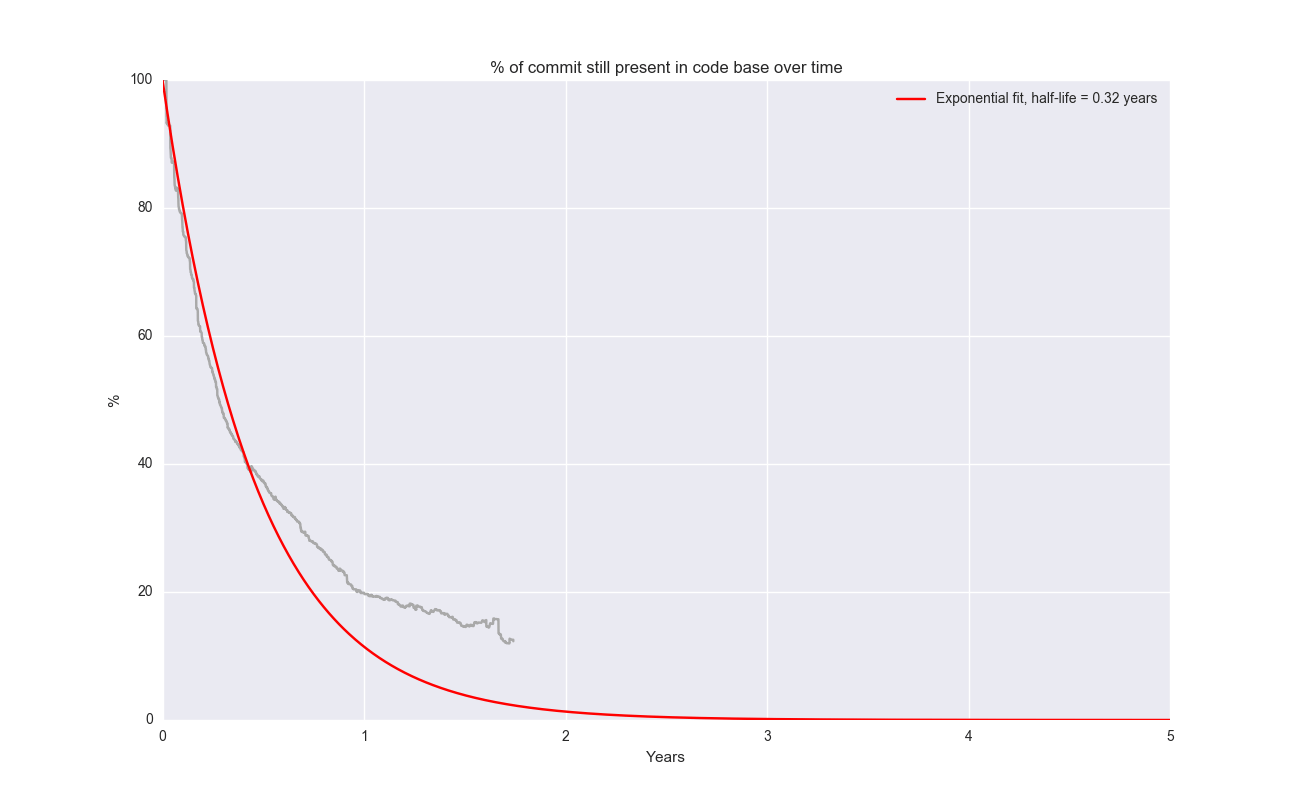
The half-life of a randomly selected line in Angular is about 0.32 years. Does this reflect on Angular? Is the architecture basically not as “linear” and consistent? You might say the comparison is unfair, because Angular is new. That’s a fair point. But I wouldn’t be surprised if it does reflect on some questionable design. Don’t mean to be shitting on Angular here, but it’s an interesting contrast.
Half-life by repository
A somewhat arbitrary sample of projects and their half-lifes:
| project | half-life (years) | first commit |
|---|---|---|
| angular | 0.32 | 2014 |
| bluebird | 0.56 | 2013 |
| kubernetes | 0.59 | 2014 |
| keras | 0.69 | 2015 |
| tensorflow | 1.08 | 2015 |
| express | 1.23 | 2009 |
| scikit-learn | 1.29 | 2011 |
| luigi | 1.30 | 2012 |
| backbone | 1.48 | 2010 |
| ansible | 1.52 | 2012 |
| react | 1.66 | 2013 |
| node | 1.76 | 2009 |
| underscore | 1.97 | 2009 |
| requests | 2.10 | 2011 |
| rails | 2.43 | 2004 |
| django | 3.38 | 2005 |
| theano | 3.71 | 2008 |
| numpy | 4.15 | 2006 |
| moment | 4.54 | 2015 |
| scipy | 4.62 | 2007 |
| tornado | 4.80 | 2009 |
| redis | 5.20 | 2010 |
| flask | 5.22 | 2010 |
| httpd | 5.38 | 1999 |
| git | 6.04 | 2005 |
| chef | 6.18 | 2008 |
| linux | 6.60 | 2005 |
It’s interesting that moment has such high half-life, but the reason is that so much of the code is locale-specific. This creates a more linear scalability with a stable core of code and linear additions over time. express is an outlier in the other direction. It’s 7 years old but code changes extremely quickly. I’m guessing this is partly because (a) lack of linear scalability in code (b) it’s probably one of the first major Javascript open source projects to hit mainstream/popularity, surfing on the Node.js wave. Possibly the code base also sucks, but I have no idea 😊
Has coding changed?
I can think of three reasons why there’s such a strong relationship between the year the project was initiated, and the half-life
- Code churns more early on in projects, and becomes more stable a while in
- Coding has changed from 2006 to 2016, and modern projects evolve faster
- There’s some kind of selection bias where the only projects that survive are the scalable stables ones
Interestingly, I don’t find any clear evidence of #1 in the data. The half-life for code written earlier in old projects are as high as late code. I’m skeptical about #3 as well because I don’t see why there would be a relation between survival and code structure (but maybe there is). My conclusion is that writing code has fundamentally changed in the last 10 years. Code really seems to change at a much faster rate in modern projects.
By the way, see discussion on Hacker News and on Reddit!
Tagged with: software, statistics, popular