Optimizing for iteration speed

I’ve written before about the importance of iterating quickly but I didn’t necessarily talk about some concrete things you can do. When I’ve built up the tech team at Better, I’ve intentionally optimized for fast iteration speed above almost everything else. What are some ways we did that?
Continuous deployment
My dubious claim is that we might be the only financial institution in the world to deploy continuously. I actually ended up getting quoted in the Economist about this specifically. We deploy to production probably 50-100 times every day. Once a pull requests is merged into master, we run a fairly extensive test suite of a few thousand unit tests and a few hundred Selenium tests. We have spent a lot of time optimizing the time it takes to run these tests so it’s really just about 15 minutes. If all tests pass, we deploy to production.
We use Buildkite for CI and run all our services on top of Kubernetes, which (among a million other things) supports blue/green deployments so that there is no downtime during deployments.
Testing
Continuous deployment is freedom under responsibility and it isn’t possible without rigorous testing. We have about 85% unit test coverage (I think the sweet spot is about 90%. 100% is unrealistic). Manual testing is only done by the product manager, generally when a feature has already been live in production for a while, to make sure that it’s according to the spec.
Do we ever release bugs to production? Of course. But mean time to recovery is usually more important than mean time between failures. If we deploy something that’s broken, we can often roll back within minutes. And since we ship very incremental changes, the average bug is often limited in impact. Bugs in production are often related to code that was written in the last few days, so it’s fresh in mind and can be fixed quickly.
No “sprints”
Two-week or three-week sprints are mini waterfall and sacrifices a lot of flexibility for the purpose of providing external stakeholders a bit more predictability. But if you work on a customer facing product, users have no expectation that you’re going to update the product at any point in time. (Even with external stakeholders, I think predictability is overrated. It’s just a way to avoid sales people overselling.)
A continuous flow of tasks means we can launch a v1, v2, and v3, all on the same day, where v2 included features that we learned from users in v1 and v3 were based on user feedback on v2.
Small tasks
Excuse me for geeking out, but an interesting result from random matrix theory is that in high dimensional spaces, local minima are rare (the reason is that most points where the derivative is zero are really saddle points). I think software engineering mostly takes place in a very high dimensional world where hill climbing by splitting up tasks into small, incremental pieces and shipping each of them separately is the fastest way to deliver value.
In contrast, one of the most scary thing in software engineering is “inventory” of code that builds up without going into production. It represents deployment risk, but also risk of building something users don’t want. Not to mention lost user value from not shipping parts of the feature earlier (user value should be thought of as feature value integrated over time, not as the feature value at the end state).
Feature flagging is a last option, and we use it sparingly. Even worse, is having feature branches. They are devil’s work and should be abolished. Git-flow is a terrible invention and when we tried it at Spotify, people spent something like 50% of their time just rebasing code.
Long-lived pull requests are frowned upon for this reason. A pull request should be merged within a few hours, ideally, and should be at most a few hundred lines. We have built our own system to assign reviewers to pull requests and notifying the Slack channel. The results are clear from the stats below – this represents the time from the point where a PR is created to the point where it’s merged, taken from our monorepo:
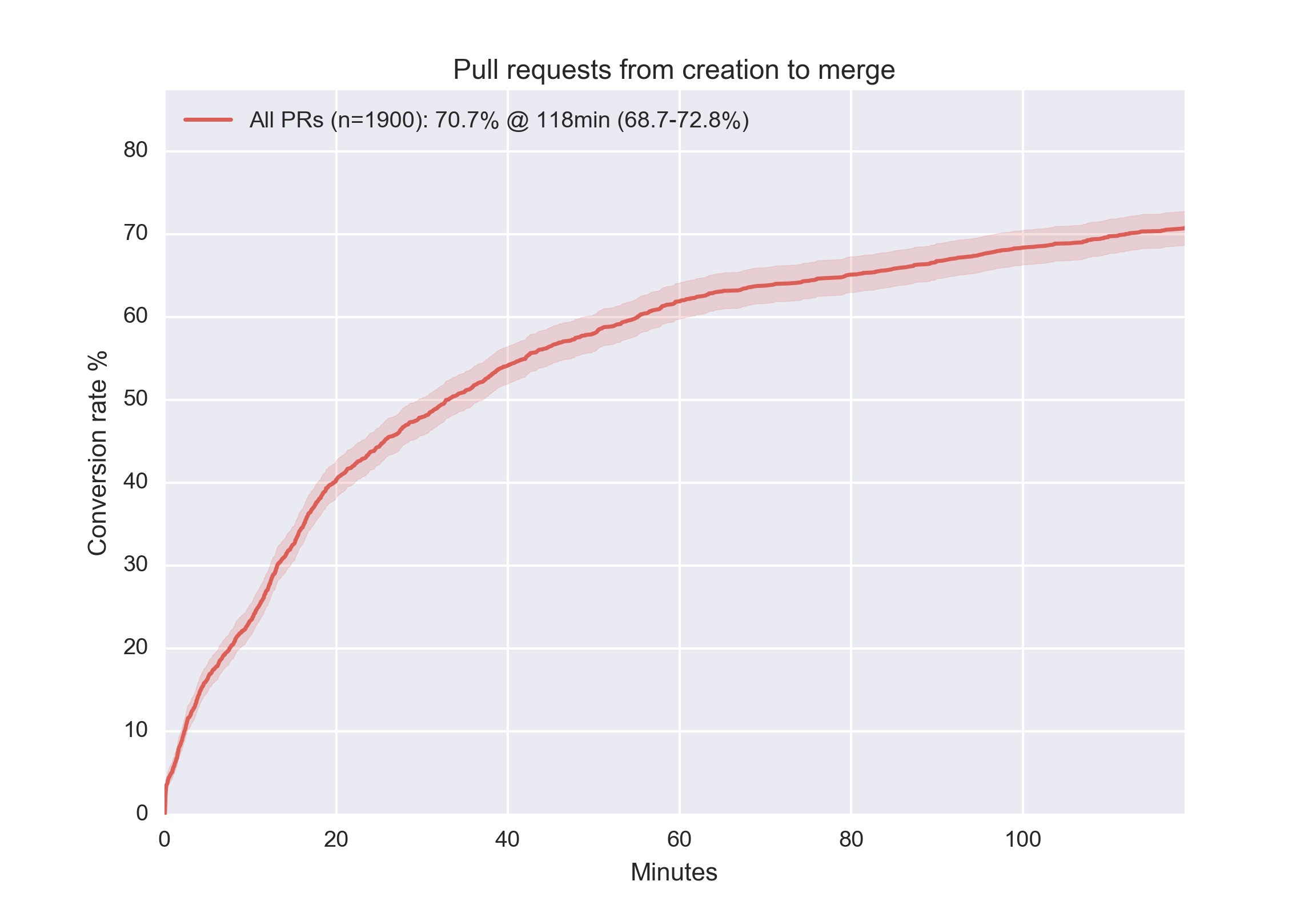
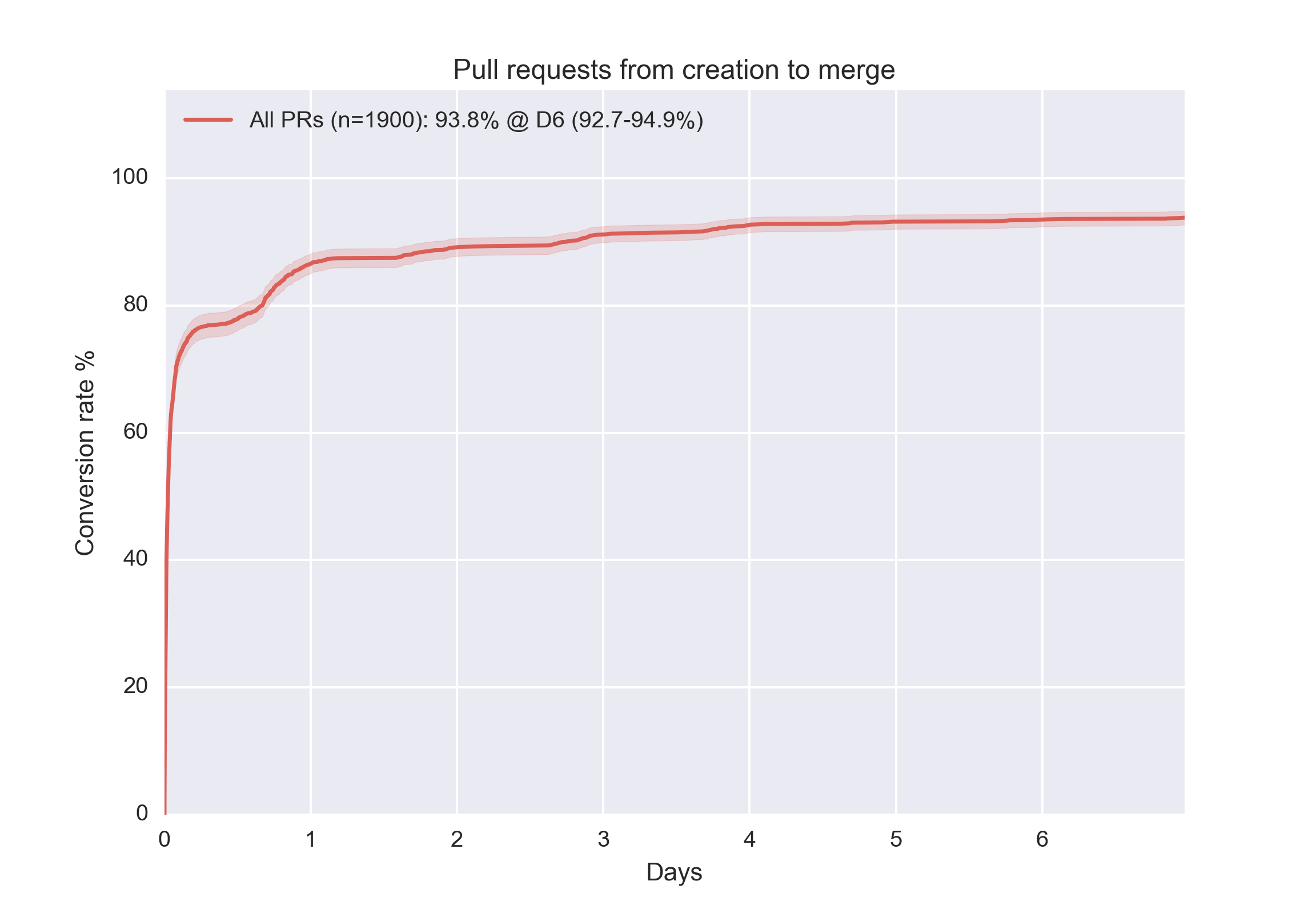
Cross-functional people and teams
Some companies have separate backend and frontend teams. Or, even worse, I once talked to a company that had a “machine learning theory team” in a different city than the “machine learning production team”. Don’t do this. It slows down iteration speed and adds coordination overhead.
If you want to optimize for a tight feedback loop, cross-functional teams make a lot more sense than teams split up by skills.
This applies to individual engineers as well. Every engineer at Better is a full-stack engineer that can take any feature in the backlog and ship it. Most of the time, the complexity is really in the backend, and so the vast majority of our team skews towards backend developers. But no one has any issue writing CSS and pushing pixels when needed. A typical task is 80-90% backend and 10-20% frontend. By having a single engineer working on a feature, we can ship a lot quicker. Most engineers in the team are not the Simone Biles of CSS, but they can do it and get the job done, and it’s usually not a big part of the work of shipping a task.
At a fast moving consumer facing startup, you can’t afford specialization. Not just do full stack engineers iterate faster, but there’s also more flexibility built in. You don’t know where in the stack the team is going to spend the next week.
Before I paint a dogmatic picture, I want to point out that we have hired a few specialized roles. We do have a test automation engineer, an operations person, and a few dedicated frontend engineers. We needed a bit more “expertise” for a few particular areas. It did take a while to get there, and even these engineers still spend some time across the whole stack.
What else?
There’s a long tail of smaller things that definitely make a huge difference:
- How can we keep the scope small and design the product process around the learning process? Much ink has been spilled on the topic of MVP, a “Minimum Viable Product”.
- Data is obviously super important How do we actually learn from the incremental features we ship? I’m talking both hard metrics here, and soft qualitative stuff.
- What about the trade-off between product quality and shipping time?
I could write about this all day long. Instead, wanted to wrap up with some notes on why cycle time matters so much.
Iterate or die
First, let me point out that optimizing for fast iteration speed is not the same thing as throughput. In Little’s law, throughput is $$ \lambda $$, and iteration speed is the inverse of $$ W $$. The relationship between $$ \lambda $$ and $$ W $$ is complex and sadly I haven’t found any good resources on it. On a Google journey you can find some decent resources from chip manufacturing among other things: 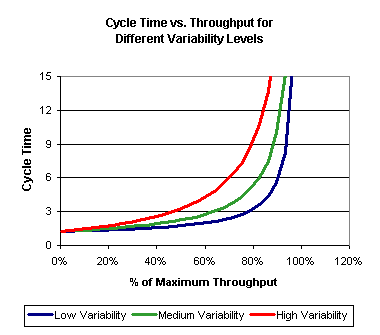
Looking at the chart it’s clear that you can lower throughput just a slight bit below the theoretical capacity and get orders of magnitude lower cycle time (i.e. higher iteration speed). But chip manufacturing is large scale manufacturing processes where there’s not even any learning process to talk about. Once you want to learn fast on top of having high throughput, it’s a no brainer to operate slightly below theoretical throughput capacity.
Sorry for getting a bit theoretical so let’s rephrase it. Imagine you’re a fast food chain that needs to make one thousand hamburgers an hour. You need to start baking the bread at some point, grill the patties, cut the lettuce etc. Everything can be done in huge batches and planned in advance. Certain software project may resemble this. For instance rewriting a big application from C++ to Java.
But far more often, a software project is like trying to find a completely new hamburger recipe. In that case, keeping the batches small, and learning from feedback continuously is key. You can make 500 or even 800 burgers an hour and make the batch size and the cycle time 10x smaller. Forcing you to keep the inventory low is a whole obsession of lean manufacturing, and it’s mostly because you can respond to customer demand much faster (the other reason was that inventory was a substantial cost in Japan in the 1950s. But I digress).
Anyway. In terms of organization – you can keep inventory much lower if people are responsible to make whole burgers rather than one person chopping the lettuce, one person making the buns, etc. And by keeping the feedback loop tight, you keep changing the combination of spices and learn from the feedback you get. Your recipe can evolve 10x or 100x faster. This is ultimately how you outcompete everyone else.
🍔
Tagged with: software, management, iteration speed, math