As some of you may know, one of my side interests is approximate nearest neighbor algorithms. I’m the author of Annoy, a library with 3,500+ stars on Github as of today. It offers fast approximate search for nearest neighbors with the additional benefit that you can load data super fast from disk using mmap. I built it at Spotify to use for music recommendations where it’s still used to power millions (maybe billions) of music recommendations every day.
One of my super nerdy interests include approximate algorithms for nearest neighbors in high-dimensional spaces. The problem is simple. You have say 1M points in some high-dimensional space. Now given a query point, can you find the nearest points out of the 1M set? Doing this fast turns out to be tricky.
I’ve been a bit bad at posting things with a regular cadence lately, partly because I’m trying to adjust to having a toddler, partly because the hunt for clicks has caused such a high bar for me that I feel like I have to post something Pulitzer-worthy. But things are always cooking, so let’s break this pattern with a quick notice on something I’ve been working on!
As you may know, one of my (very geeky) interests is Approximate nearest neigbor methods, and I’m the author of a Python package called Annoy.
I’ve also built a benchmark suite called ann-benchmarks to compare different packages. Annoy was the world’s fastest package for a few months, but two things happened.
This is another post based on my talk at NYC Machine Learning. The previous two parts covered most of the interesting parts, but there are still some topics left to be discussed. To go back and read the meaty stuff, check out
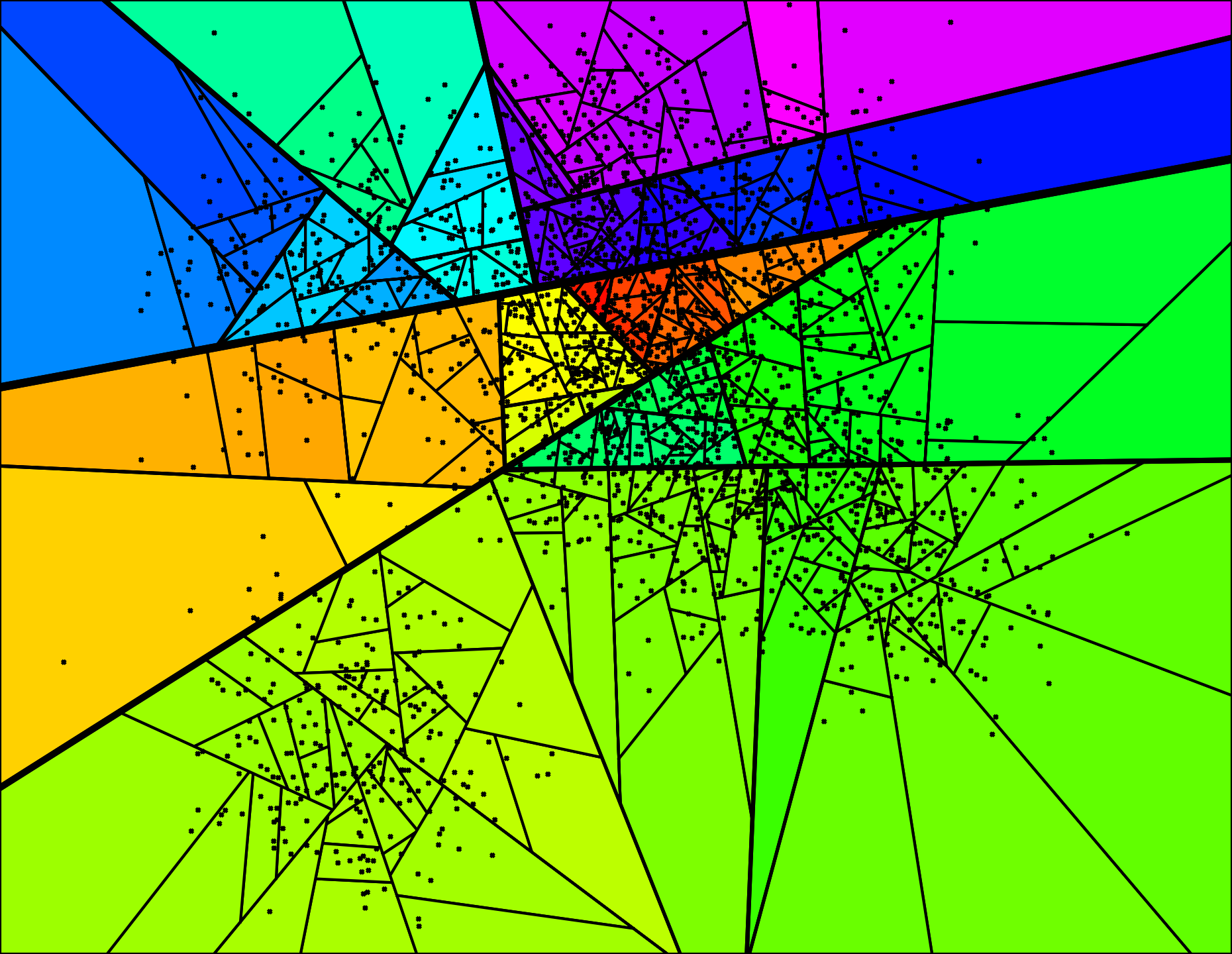
This is a blog post rewritten from a presentation at NYC Machine Learning on Sep 17. It covers a library called Annoy that I have built that helps you do nearest neighbor queries in high dimensional spaces. In the first part, I went through some examples of why vector models are useful. In the second part I will be explaining the data structures and algorithms that Annoy uses to do approximate nearest neighbor queries.
This is a blog post rewritten from a presentation at NYC Machine Learning last week. It covers a library called Annoy that I have built that helps you do (approximate) nearest neighbor queries in high dimensional spaces. I will be splitting it into several parts. This first talks about vector models, how to measure similarity, and why nearest neighbor queries are useful.
Annoy is a library written by me that supports fast approximate nearest neighbor queries. Say you have a high (1-1000) dimensional space with points in it, and you want to find the nearest neighbors to some point. Annoy gives you a way to do this very quickly. It could be points on a map, but also word vectors in a latent semantic representation or latent item vectors in collaborative filtering.
Annoy is a C++/Python package I built for fast approximate nearest neighbor search in high dimensional spaces. Spotify uses it a lot to find similar items. First, matrix factorization gives a low dimensional representation of each item (artist/album/track/user) so that every item is a k-dimensional vector, where k is typically 40-100. This is then loaded into an Annoy index for a number of things: fast similar items, personal music recommendations, etc.