There is no magic trick
(Warning: super speculative, feel free to ignore)
As Yogi Berra said, “It’s tough to make predictions, especially about the future”. Unfortunately predicting is hard, and unsurprisingly people look for the Magic Trick™ that can resolve all the uncertainty. Whether it’s recruiting, investing, system design, finding your soulmate, or anything else, there’s always an alleged shortcut.
In the famous book Expert Political Judgment a huge amount of forecasts about the future are tracked over a long time. The conclusion is: people suck at forecasting. The only characteristic that seems somewhat predictive is what the author calls being a hedgehog vs being a fox. Hedgehogs (bad) are people who have one mental model they apply to anything. Foxes (good) apply a huge amount of different model and combine them to arrive at a conclusion. (Confusingly, hedgehogs do not hedge their bets).
This is a quite profound conclusion that goes beyond prediction. In fact I see it in almost any hard decision I have to make.
Let’s think about recruiting, for instance. So many people claim to have found the ultimate interview question. It ranges from “how old were you when you started coding?” to “what are your open source contributions” to “please spend ten hours on this take home assignment”.
After probably 500 tech interviews I’ve realized one thing: there is no trick. Empirically the correlation between who I thought would be good and who actually turned out to be good is very small. The overconfidence effect definitely is a real thing and I’ve become more skeptical about my abilities. The one thing I’ve learned is: try to collect as many independent metrics as you can. The other day I actually came across an old paper saying something similar.
The same thing applies to investing. You might follow Peter Thiel’s advice and never invest in companies where they wear suits. Or you might have an extremely strong conviction that self-driving cars will take over so you go out and short GM’s stock. But remember you’re up against professional portfolio managers who stare at their screens for 14 hours per day. Did they miss something you are seeing? No. They know that what you are seeing is a small fraction of their valuation of a company.

What makes it even worse is both investing and recruiting are activities that takes place in a market. You are fighting with n other actors to find mispricings and arbitrage opportunity. Just like buying stocks based on a single model is bad, recruiting based on a single model will give you bad candidates. What happens is basically adverse selection and it will cause you to overpay for underperformance.
See below for a very silly market model where two companies X (blue) and Y (red) bid on employees but X knows something that Y doesn’t know. I model that by assuming employees break down into a set of random factors and X know a few more factors than Y know. Click the graph to see the code.
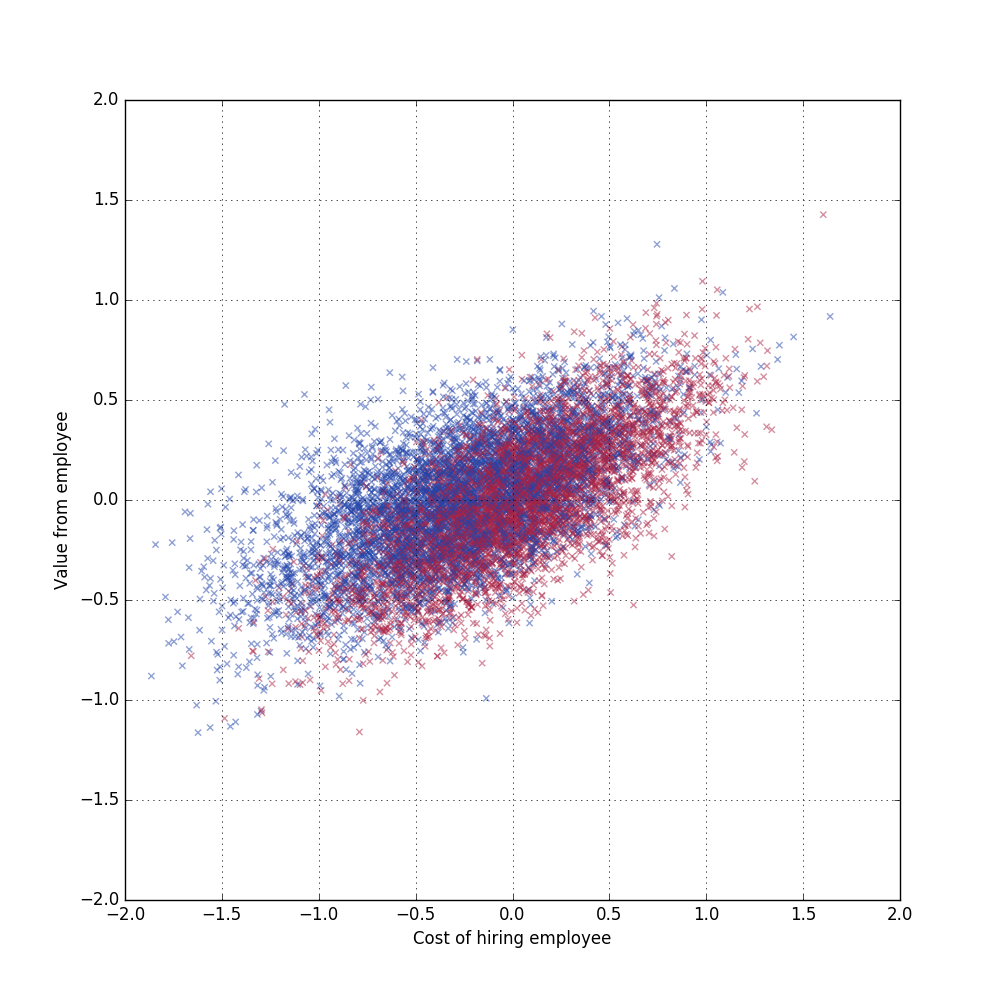
It’s better to be further to the left (lower cost) and higher up (more value) for a company.
It’s a bit hard to see from the model but what happens is the total total surplus (value – cost) for company X is some positive number and for Y it’s approximately zero. This holds true any time company X knows just a bit more about employees than company Y. Warren Buffet once said: “If you’ve been playing poker for half an hour and you still don’t know who the patsy is, you’re the patsy.”
Speaking of models, one of the most useful insights from machine learning is how much value you get from combining many models. This has been the central dogma in the machine learning community for a long time, whether it’s Kaggle, or the Netflix Prize, or industry applications. All models are wrong, but some are useful – combining a bunch of those models will always outperform.
I think the best meta-model for how to think of any complex systems, whether it’s recruiting or investing or anything else, is something like boosting. You start with nothing, then you find the best model that explains what you see. Then you increase the weight of the misclassified examples and fit another model (weak learner, in boosting lingo). And so on. Eventually you have built up a set of simple models that you can combine for a final prediction. (As a side note I think the reason humans can do this so well is they can use priors very efficiently)
Peter Thiel’s advice is a set of models that are wrong, but still marginally useful, so why not include them? Does a company have network effect? Sure, marginally helpful. Does a candidate have an MBA? Etc. These all sound like weak learners to me. Using just one of them is pretty bad. Add up 100 of them and you have a pretty good prediction.
Tagged with: misc, business, philosophy