Why are new startups growing so fast?
Why is the wage distribution getting larger for software engineers?
Why do I love infrastructure?
Is open source dead?
I think a lot of these things, and some more things, all have their roots in a big shift in how we build software.
Or rather, how we buy software.
Software development today is a lot about using the right vendors rather than building technology yourself.
Writing code for a computer is hard enough.
You take something big and fuzzy, some large vague business outcome you want to achive.
Then you break it down recursively and think about all the cases until you have clear logical statements a computer can follow.
Computers are very good at following logical statements.
CIA produced a fantastic book during the peak of World War 2 called Simple Sabotage. It laid out various ways for infiltrators to ruin productivity of a company. Some of the advice is timeless, for instance the section about “General interference with Organizations and Production”:
Long story short: I’m working on a super cool tool called Modal. Please check it out — it lets you run things in the cloud without having to think about infrastructure. Scaling out, scheduling, containerization, using GPUs, setting up webhooks, and all kinds of other stuff. It’s primarily meant for data teams. We aren’t quite live, but you can sign up for our waitlist.
This is is in many respects a successor to a
blog post I wrote last year
about what I want from software infrastructure, but the ideas morphed in my head into something sort of wider.
The genesis
I encountered AWS in 2006 or 2007 and remember thinking that it’s crazy — why would anyone want to put their stuff in someone else’s data center?
But only a couple of years later, I was running a bunch of stuff on top of AWS.
Hi! It’s your friendly project management theorician. You might remember me from blog posts such as Why software projects take longer than you think, which is a blog post I wrote a long time ago positing that software projects completion time follow a log-normal distribution.
Software infrastructure (by which I include everything ending with *aaS, or anything remotely similar to it) is an exciting field, in particular because (despite what the neo-luddites may say) it keeps getting better every year! I love working with something that moves so quickly.
It’s a popular attitude among developers to rant about our tools and how broken things are. Maybe I’m an optimistic person, because my viewpoint is the complete opposite! I had my first job as a software engineer in 1999, and in the last two decades I’ve seen software engineering changing in ways that have made us orders of magnitude more productive. Just some examples from things I’ve worked on or close to:
I spent a ton of time looking at different software providers, both as a CTO, and as a nerd “advanced” consumer who builds stuff in my spare time. In the last 10 years, there has been an order of magnitude more products that cater directly to developers, through APIs, SDKs, and tooling. I’m pretty psyched about this trend. As the cost of building software goes down, that drives up the demand for software engineers. That then drives up the demand for even more products built for software engineers. That then drives down the cost of building software even more!
Anyone who built software for a while knows that estimating how long something is going to take is hard.
It’s hard to come up with an unbiased estimate of how long something will take, when fundamentally the work in itself is about solving something.
One pet theory I’ve had for a really long time, is that some of this is really just a statistical artifact.
A modern tech stack typically involves at least a frontend and backend but relatively quickly also grows to include a data platform. This typically grows out of the need for ad-hoc analysis and reporting but possibly evolves into a whole oil refinery of cronjobs, dashboards, bulk data copying, and much more. What generally pushes things into the data platform is (generally) that a number of things are
Why? Because I’ve been sitting in 100,000,000 meetings where people endlessly debate whether the monthly number of widgets is going up or down, or whether widget method X is more productive than widget method Y. For almost any graph, quantifying the uncertainty seems useful, so I started trying. A few months later:
This is a bit of a rant but I really don’t like software that invents its own query language. There’s a trillion different ORMs out there. Another trillion databases with their own query language. Another trillion SaaS products where the only way to query is to learn some random query DSL they made up.
Ok, so I have to first preface this whole blog post by a few things:
I really struggle with the term microservices. I can’t put my finger on exactly why. Maybe because the term is hopelessly ill-defined, maybe because it’s gotten picked up by the hype train. Whatever. But I have to stick to some type of terminology so let’s just roll with it.
This blog post might be mildly controversial, but I’m throwing it out there because I’ve had this itchy feeling for so long and I can’t get rid of it. I respect it if you want to disagree vehemently, and maybe there’s something both of us can learn.
I have a weird story. My first “real” company, Spotify, used a service-oriented architecture from scratch. I also spent some time at Google which used a service-oriented architecture. So basically since 2006 I’ve been continuously working in what people now call a “microservice architecture”. It didn’t even occur to me that some people might want to build things as monoliths. So I guess I’m coming at it from a different direction than many other. Either way, there were particular non-standard reasons why Spotify and Google had to do this that I’ll get back to later.
I’ve been reading up on operations research lately, including queueing theory. It started out as a way to understand the very complex mortgage process (I work at a mortgage startup) but it’s turned into my little hammer and now I see nails everywhere.
I spent a few days during the holidays fixing up a bunch of semi-dormant open source projects and I have a couple of blog posts in the pipeline about various updates. First up, I made a number of fixes to Git of Theseus which is a tool (written in Python) that generates statistics about Git repositories. I’ve written about it previously on this blog. The name is a horrible pun (I’m a dad!) on Ship of Theseus which is a philosophical thought experiment about what happens if you replace every single part of a boat — is it still the same boat ⁉️ 🤔
Here’s a dumb extremely accurate rule I’m postulating* for software engineering projects: you need at least 3 examples before you solve the right problem.
This is what I’ve noticed:
Don’t factor out shared code between two classes. Wait until you have at least three.
The two first attempts to solve a problem will fail because you misunderstood the problem. The third time it will work.
Any attempt at being smart earlier will end up overfitting to coincidental patterns.
(Note that #1 and #2 are actually pretty different implications. But let’s get back to that later.)
I’ve written before about the importance of iterating quickly but I didn’t necessarily talk about some concrete things you can do. When I’ve built up the tech team at Better, I’ve intentionally optimized for fast iteration speed above almost everything else. What are some ways we did that?
I was reading yet another blog post titled “Why our team moved from <language X> to <language Y>” (I forgot which one) and I started wondering if you can generalize it a bit. Is it possible to generate a N * N contingency table of moving from language X to language Y?
As a project evolves, does the new code just add on top of the old code? Or does it replace the old code slowly over time? In order to understand this, I built a little thing to analyze Git projects, with help from the formidable GitPython project. The idea is to go back in history historical and run a git blame (making this somewhat fast was a bit nontrivial, as it turns out, but I’ll spare you the details, which involve some opportunistic caching of files, pick historical points spread out in time, use git diff to invalidate changed files, etc).
I generally haven’t written much about software architecture. People make heuristics into religion. But here is something I thought about: how to build in self-correction into systems. This has been something just vaguely sitting in my head lacking a clear conceptual definition until a whole slew of things popped up today that all had the exact same issue at its core. I’m going to refer to it as state drift lacking a better term for it.
Here’s a conclusion I’ve made building consumer products for many years: the speed at which a company innovates is limited by its iteration speed.
I don’t even mean throughput here. I just mean the cycle time. Invoking Little’s law this is also related to the total inventory of features not being deployed yet.
The easiest way to be a 10x engineer is to make 10 other engineers 2x more efficient. Someone can be a 10x engineer if they do nothing for 364 days then convinces the team to change programming language to a 2x more productive language.
A motivated 10x engineer in one team could be a demotivated 0.5x engineer in another team (and vice versa).
A average 1x engineer could easily become a 5x engineer if surrounded by 10x engineers. Engagement and work ethics is contagious.
The cynical reason why 10x engineers aren’t paid 10x more salary is that there is no way for the new employer to know. There is no “10x badge”.
…but also, a 10x engineer can go to a new company and become an 1x engineer because of bad focus / bad engagement / tech stack mismatch.
So unfortunately there’s less economic rationality for companies to pay 10x salaries to 10x engineers (contrary to what Google or Netflix says)
There’s no such thing as a 10x engineer spending time on something that never ends up delivering business value. If something doesn’t deliver business value, it’s 0x.
If you build something that the average engineer would not have been able to build, no matter how much time, that can make you 100x or 1000x, or ∞x. Quoting Alexander Scott: There is no number of ordinary eight-year-olds who, when organized into a team, will become smart enough to beat a grandmaster in chess.
Most of the 10x factor is most likely explained by team and company factors (process, tech stack, etc) and applies to everyone in the team/company. Intra-team variation is thus much smaller than 10x (even controlling for the fact that companies tend to attract people of equal caliber). Nature vs nurture…
I’ve never met the legendary “10x jerk”. Anecdotally the outperforming engineers are generally nice and humble.
Don’t get hung up on the exact numbers here, it’s just for illustration purposes. I.e. someone introduced a bug in the trading system of Knight Capital that made them lose $465M in 30 minutes. Did that make it a -1,000,000x engineer? (and btw it had more to do with company culture). The numbers aren’t meant to be taken literally.
Curious about Google’s newly released TensorFlow? I don’t have a beefy GPU machine, so I spent some time getting it to run on EC2. The steps on how to reproduce it are pretty brutal and I wouldn’t recommend going through it unless you want to waste five hours of your live.
Every once in a while when talking to smart people the topic of automation comes up. Technology has made lots of occupations redundant, so what’s next?
Switchboard operator, a long time ago
What about software engineers? Every year technology replaces parts of what they do. Eventually surely everything must be replaced? I just ran into another one of these arguments: Software Engineers will be obsolete by 2060.
Wow I guess it was more than a year ago that I tweeted this. Crazy how time flies by. Anyway, here’s my rationale:
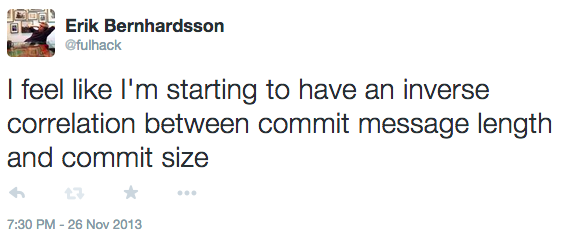
When I update one line of code I feel like I have to put in a long explanation about its side effects, why it’s fully backwards compatible, and why it fixes some issue #xyz.
When I refactor 500 lines of code, I get too lazy to write anything sensible, so I just put “refactoring FooBarController”. Note: don’t do at home!
I decided to plot the relationship for Luigi:
{% include 2015-02-26-the-relationship-between-commit-size-and-commit-message-size.html %}